
Preface
In order to draw things in 2D, we usually rely on lines, which typically get classified into two categories: straight lines, and curves. The first of these are as easy to draw as they are easy to make a computer draw. Give a computer the first and last point in the line, and BAM! straight line. No questions asked.
Curves, however, are a much bigger problem. While we can draw curves with ridiculous ease freehand, computers are a bit handicapped in that they can't draw curves unless there is a mathematical function that describes how it should be drawn. In fact, they even need this for straight lines, but the function is ridiculously easy, so we tend to ignore that as far as computers are concerned; all lines are "functions", regardless of whether they're straight or curves. However, that does mean that we need to come up with fast-to-compute functions that lead to nice looking curves on a computer. There are a number of these, and in this article we'll focus on a particular function that has received quite a bit of attention and is used in pretty much anything that can draw curves: Bézier curves.
They're named after Pierre Bézier, who is principally responsible for making them known to the world as a curve well-suited for design work (publishing his investigations in 1962 while working for Renault), although he was not the first, or only one, to "invent" these type of curves. One might be tempted to say that the mathematician Paul de Casteljau was first, as he began investigating the nature of these curves in 1959 while working at Citroën, and came up with a really elegant way of figuring out how to draw them. However, de Casteljau did not publish his work, making the question "who was first" hard to answer in any absolute sense. Or is it? Bézier curves are, at their core, "Bernstein polynomials", a family of mathematical functions investigated by Sergei Natanovich Bernstein, whose publications on them date back at least as far as 1912.
Anyway, that's mostly trivia, what you are more likely to care about is that these curves are handy: you can link up multiple Bézier curves so that the combination looks like a single curve. If you've ever drawn Photoshop "paths" or worked with vector drawing programs like Flash, Illustrator or Inkscape, those curves you've been drawing are Bézier curves.
But what if you need to program them yourself? What are the pitfalls? How do you draw them? What are the bounding boxes, how do you determine intersections, how can you extrude a curve, in short: how do you do everything that you might want to do with these curves? That's what this page is for. Prepare to be mathed!
Virtually all Bézier graphics are interactive.
This page uses interactive examples, relying heavily on Bezier.js, as well as maths formulae which are typeset into SVG using the XeLaTeX typesetting system and pdf2svg by David Barton.
This book is open source.
This book is an open source software project, and lives on two github repositories. The first is https://github.com/pomax/bezierinfo and is the purely-for-presentation version you are viewing right now. The other repository is https://github.com/pomax/BezierInfo-2, which is the development version, housing all the code that gets turned into the web version, and is also where you should file issues if you find bugs or have ideas on what to change or add to the primer.
How complicated is the maths going to be?
Most of the mathematics in this Primer are early high school maths. If you understand basic arithmetic, and you know how to read English, you should be able to get by just fine. There will at times be far more complicated maths, but if you don't feel like digesting them, you can safely skip over them by either skipping over the "detail boxes" in section or by just jumping to the end of a section with maths that looks too involving. The end of sections typically simply list the conclusions so you can just work with those values directly.
What language is all this example code in?
There are way too many programming languages to favour one of all others, soo all the example code in this Primer uses a form of pseudo-code that uses a syntax that's close enough to, but not actually, modern scripting languages like JS, Python, etc. That means you won't be able to copy-paste any of it without giving it any thought, but that's intentional: if you're reading this primer, presumably you want to learn, and you don't learn by copy-pasting. You learn by doing things yourself, making mistakes, and then fixing those mistakes. Now, of course, I didn't intentionally add errors in the example code just to trick you into making mistakes (that would be horrible!) but I did intentionally keep the code from favouring one programming language over another. Don't worry though, if you know even a single procedural programming language, you should be able to read the examples without any difficulties.
Questions, comments:
If you have suggestions for new sections, hit up the Github issue tracker (also reachable from the repo linked to in the upper right). If you have questions about the material, there's currently no comment section while I'm doing the rewrite, but you can use the issue tracker for that as well. Once the rewrite is done, I'll add a general comment section back in, and maybe a more topical "select this section of text and hit the 'question' button to ask a question about it" system. We'll see.
Help support the book!
If you enjoyed this book, or you simply found it useful for something you were trying to get done, and you were wondering how to let me know you appreciated this book, you have two options: you can either head on over to the Patreon page for this book, or if you prefer to make a one-time donation, head on over to the buy Pomax a coffee page. This work has grown from a small primer to a 100-plus print-page-equivalent reader on the subject of Bézier curves over the years, and a lot of coffee went into the making of it. I don't regret a minute I spent on writing it, but I can always do with some more coffee to keep on writing!
What's new?
This primer is a living document, and so depending on when you last look at it, there may be new content. Click the following link to expand this section to have a look at what got added, when, or click through to the News posts for more detailed updates. (RSS feed available)
November 2020
Added a section on finding curve/circle intersections
October 2020
Added the Ukranian locale! Help out in getting its localization to 100%!
August-September 2020
-
Completely overhauled the site: the Primer is now a normal web page that works fine with JS disabled, but obviously better with JS turned on.
June 2020
Added automatic CI/CD using Github Actions
January 2020
Added reset buttons to all graphics
Updated to preface to correctly describe the on-page maths
Fixed the Catmull-Rom section because it had glaring maths errors
August 2019
Added a section on (plain) rational Bezier curves
Improved the Graphic component to allow for sliders
December 2018
Added a section on curvature and calculating kappa.
-
Added a Patreon page! Head on over to patreon.com/bezierinfo to help support this site!
August 2018
Added a section on finding a curve's y, if all you have is the x coordinate.
July 2018
Rewrote the 3D normals section, implementing and explaining Rotation Minimising Frames.
Updated the section on curve order raising/lowering, showing how to get a least-squares optimized lower order curve.
-
(Finally) updated 'npm test' so that it automatically rebuilds when files are changed while the dev server is running.
June 2018
Added a section on direct curve fitting.
Added source links for all graphics.
Added this "What's new?" section.
April 2017
Added a section on 3d normals.
Added live-updating for the social link buttons, so they always link to the specific section you're reading.
February 2017
Finished rewriting the entire codebase for localization.
January 2016
Added a section to explain the Bezier interval.
Rewrote the Primer as a React application.
December 2015
Set up the split repository between BezierInfo-2 as development repository, and bezierinfo as live page.
-
Removed the need for client-side LaTeX parsing entirely, so the site doesn't take a full minute or more to load all the graphics.
May 2015
Switched over to pure JS rather than Processing-through-Processing.js
Added Cardano's algorithm for finding the roots of a cubic polynomial.
April 2015
Added a section on arc length approximations.
February 2015
Added a section on the canonical cubic Bezier form.
November 2014
Switched to HTTPS.
July 2014
Added the section on arc approximation.
April 2014
Added the section on Catmull-Rom fitting.
November 2013
Added the section on Catmull-Rom / Bezier conversion.
Added the section on Bezier cuves as matrices.
April 2013
Added a section on poly-Beziers.
Added a section on boolean shape operations.
March 2013
First drastic rewrite.
Added sections on circle approximations.
Added a section on projecting a point onto a curve.
Added a section on tangents and normals.
Added Legendre-Gauss numerical data tables.
October 2011
-
First commit for the bezierinfo site, based on the pre-Primer webpage that covered the basics of Bezier curves in HTML with Processing.js examples.
A lightning introduction
Let's start with the good stuff: when we're talking about Bézier curves, we're talking about the things that you can see in the following graphics. They run from some start point to some end point, with their curvature influenced by one or more "intermediate" control points. Now, because all the graphics on this page are interactive, go manipulate those curves a bit: click-drag the points, and see how their shape changes based on what you do.

These curves are used a lot in computer aided design and computer aided manufacturing (CAD/CAM) applications, as well as in graphic design programs like Adobe Illustrator and Photoshop, Inkscape, GIMP, etc. and in graphic technologies like scalable vector graphics (SVG) and OpenType fonts (TTF/OTF). A lot of things use Bézier curves, so if you want to learn more about them... prepare to get your learn on!
So what makes a Bézier Curve?
Playing with the points for curves may have given you a feel for how Bézier curves behave, but what are Bézier curves, really? There are two ways to explain what a Bézier curve is, and they turn out to be the entirely equivalent, but one of them uses complicated maths, and the other uses really simple maths. So... let's start with the simple explanation:
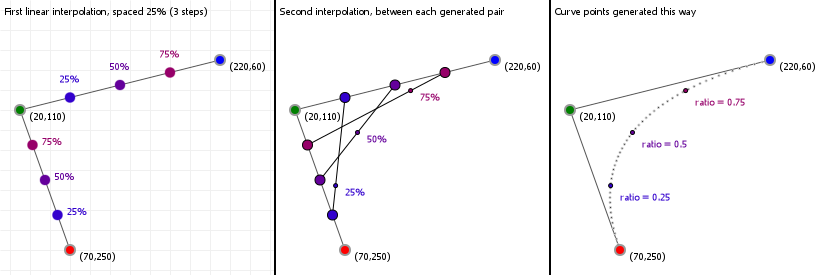
Bézier curves are the result of linear interpolations. That sounds complicated but you've been doing linear interpolation since you were very young: any time you had to point at something between two other things, you've been applying linear interpolation. It's simply "picking a point between two points".
If we know the distance between those two points, and we want a new point that is, say, 20% the distance away from the first point (and thus 80% the distance away from the second point) then we can compute that really easily:

So let's look at that in action: the following graphic is interactive in that you can use your up and down arrow keys to increase or decrease the interpolation ratio, to see what happens. We start with three points, which gives us two lines. Linear interpolation over those lines gives us two points, between which we can again perform linear interpolation, yielding a single point. And that point —and all points we can form in this way for all ratios taken together— form our Bézier curve:
And that brings us to the complicated maths: calculus.
While it doesn't look like that's what we've just done, we actually just drew a quadratic curve, in steps, rather than in a single go. One of the fascinating parts about Bézier curves is that they can both be described in terms of polynomial functions, as well as in terms of very simple interpolations of interpolations of [...]. That, in turn, means we can look at what these curves can do based on both "real maths" (by examining the functions, their derivatives, and all that stuff), as well as by looking at the "mechanical" composition (which tells us, for instance, that a curve will never extend beyond the points we used to construct it).
So let's start looking at Bézier curves a bit more in depth: their mathematical expressions, the properties we can derive from them, and the various things we can do to, and with, Bézier curves.
The mathematics of Bézier curves
Bézier curves are a form of "parametric" function. Mathematically speaking, parametric functions are cheats: a "function" is actually a well defined term representing a mapping from any number of inputs to a single output. Numbers go in, a single number comes out. Change the numbers that go in, and the number that comes out is still a single number.
Parametric functions cheat. They basically say "alright, well, we want multiple values coming out, so we'll just use more than one function". An illustration: Let's say we have a function that maps some value, let's call it x, to some other value, using some kind of number manipulation:

The notation f(x) is the standard way to show that it's a function (by convention called f if we're only listing one) and its output changes based on one variable (in this case, x). Change x, and the output for f(x) changes.
So far, so good. Now, let's look at parametric functions, and how they cheat. Let's take the following two functions:

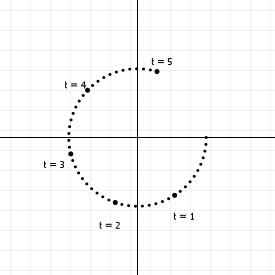
There's nothing really remarkable about them, they're just a sine and cosine function, but you'll notice the inputs have different names. If we change the value for a, we're not going to change the output value for f(b), since a isn't used in that function. Parametric functions cheat by changing that. In a parametric function all the different functions share a variable, like this:

Multiple functions, but only one variable. If we change the value for t, we change the outcome of both fa(t) and fb(t). You might wonder how that's useful, and the answer is actually pretty simple: if we change the labels fa(t) and fb(t) with what we usually mean with them for parametric curves, things might be a lot more obvious:

There we go. x/y coordinates, linked through some mystery value t.
So, parametric curves don't define a y coordinate in terms of an x coordinate, like normal functions do, but they instead link the values to a "control" variable. If we vary the value of t, then with every change we get two values, which we can use as (x,y) coordinates in a graph. The above set of functions, for instance, generates points on a circle: We can range t from negative to positive infinity, and the resulting (x,y) coordinates will always lie on a circle with radius 1 around the origin (0,0). If we plot it for t from 0 to 5, we get this:
Bézier curves are just one out of the many classes of parametric functions, and are characterised by using the same base function for all of the output values. In the example we saw above, the x and y values were generated by different functions (one uses a sine, the other a cosine); but Bézier curves use the "binomial polynomial" for both the x and y outputs. So what are binomial polynomials?
You may remember polynomials from high school. They're those sums that look like this:

If the highest order term they have is x³, they're called "cubic" polynomials; if it's x², it's a "square" polynomial; if it's just x, it's a line (and if there aren't even any terms with x it's not a polynomial!)
Bézier curves are polynomials of t, rather than x, with the value for t being fixed between 0 and 1, with coefficients a, b etc. taking the "binomial" form, which sounds fancy but is actually a pretty simple description for mixing values:

I know what you're thinking: that doesn't look too simple! But if we remove t and add in "times one", things suddenly look pretty easy. Check out these binomial terms:

Notice that 2 is the same as 1+1, and 3 is 2+1 and 1+2, and 6 is 3+3... As you can see, each time we go up a dimension, we simply start and end with 1, and everything in between is just "the two numbers above it, added together", giving us a simple number sequence known as Pascal's triangle. Now that's easy to remember.
There's an equally simple way to figure out how the polynomial terms work: if we rename (1-t) to a and t to b, and remove the weights for a moment, we get this:

It's basically just a sum of "every combination of a and b", progressively replacing a's with b's after every + sign. So that's actually pretty simple too. So now you know binomial polynomials, and just for completeness I'm going to show you the generic function for this:

And that's the full description for Bézier curves. Σ in this function indicates that this is a series of additions (using the variable listed below the Σ, starting at ...=<value> and ending at the value listed on top of the Σ).
How to implement the basis function
We could naively implement the basis function as a mathematical construct, using the function as our guide, like this:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 |
I say we could, because we're not going to: the factorial function is incredibly expensive. And, as we can see from the above explanation, we can actually create Pascal's triangle quite easily without it: just start at [1], then [1,1], then [1,2,1], then [1,3,3,1], and so on, with each next row fitting 1 more number than the previous row, starting and ending with "1", with all the numbers in between being the sum of the previous row's elements on either side "above" the one we're computing.
We can generate this as a list of lists lightning fast, and then never have to compute the binomial terms because we have a lookup table:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 | |
| 14 | |
| 15 | |
| 16 | |
| 17 | |
| 18 |
So what's going on here? First, we declare a lookup table with a size that's reasonably large enough to accommodate most lookups. Then, we declare a function to get us the values we need, and we make sure that if an n/k pair is requested that isn't in the LUT yet, we expand it first. Our basis function now looks like this:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 |
Perfect. Of course, we can optimize further. For most computer graphics purposes, we don't need arbitrary curves (although we will also provide code for arbitrary curves in this primer); we need quadratic and cubic curves, and that means we can drastically simplify the code:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 |
And now we know how to program the basis function. Excellent.
So, now we know what the basis function looks like, time to add in the magic that makes Bézier curves so special: control points.
Controlling Bézier curvatures
Bézier curves are, like all "splines", interpolation functions. This means that they take a set of points, and generate values somewhere "between" those points. (One of the consequences of this is that you'll never be able to generate a point that lies outside the outline for the control points, commonly called the "hull" for the curve. Useful information!). In fact, we can visualize how each point contributes to the value generated by the function, so we can see which points are important, where, in the curve.
The following graphs show the interpolation functions for quadratic and cubic curves, with "S" being the strength of a point's contribution to the total sum of the Bézier function. Click-and-drag to see the interpolation percentages for each curve-defining point at a specific t value.
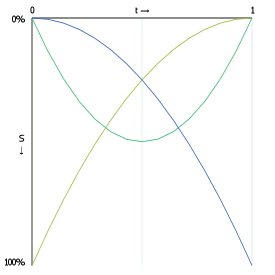
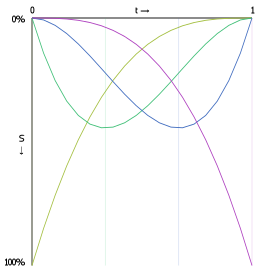
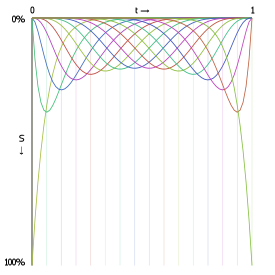
Also shown is the interpolation function for a 15th order Bézier function. As you can see, the start and end point contribute considerably more to the curve's shape than any other point in the control point set.
If we want to change the curve, we need to change the weights of each point, effectively changing the interpolations. The way to do this is about as straightforward as possible: just multiply each point with a value that changes its strength. These values are conventionally called "weights", and we can add them to our original Bézier function:

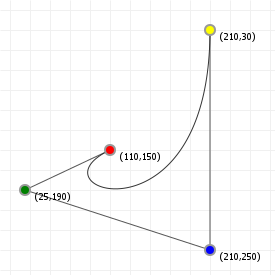
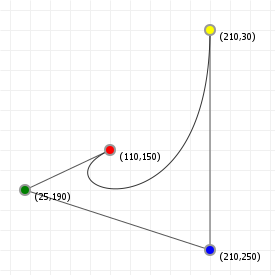
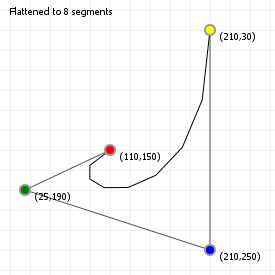
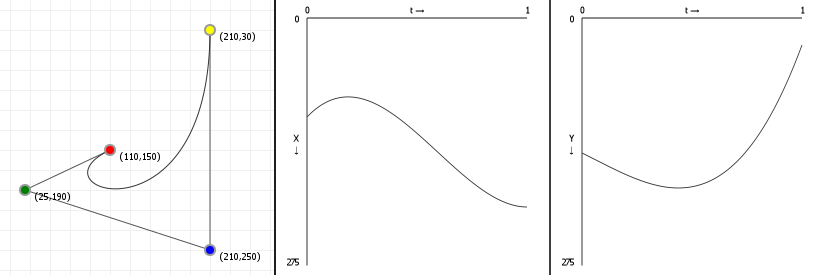
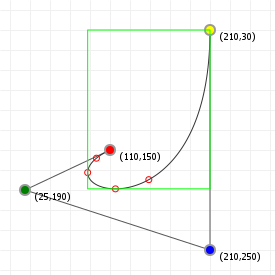
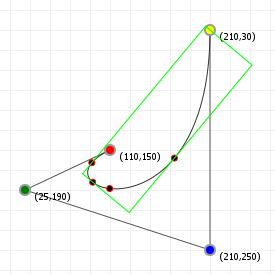
That looks complicated, but as it so happens, the "weights" are actually just the coordinate values we want our curve to have: for an nth order curve, w0 is our start coordinate, wn is our last coordinate, and everything in between is a controlling coordinate. Say we want a cubic curve that starts at (110,150), is controlled by (25,190) and (210,250) and ends at (210,30), we use this Bézier curve:

Which gives us the curve we saw at the top of the article:
What else can we do with Bézier curves? Quite a lot, actually. The rest of this article covers a multitude of possible operations and algorithms that we can apply, and the tasks they achieve.
How to implement the weighted basis function
Given that we already know how to implement basis function, adding in the control points is remarkably easy:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 |
And now for the optimized versions:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 |
And now we know how to program the weighted basis function.
Controlling Bézier curvatures, part 2: Rational Béziers
We can further control Bézier curves by "rationalising" them: that is, adding a "ratio" value in addition to the weight value discussed in the previous section, thereby gaining control over "how strongly" each coordinate influences the curve.
Adding these ratio values to the regular Bézier curve function is fairly easy. Where the regular function is the following:

The function for rational Bézier curves has two more terms:

In this, the first new term represents an additional weight for each coordinate. For example, if our ratio values are [1, 0.5, 0.5, 1]
then ratio0 = 1, ratio1 = 0.5, and so on, and is effectively identical as if we were just
using different weight. So far, nothing too special.
However, the second new term is what makes the difference: every point on the curve isn't just a "double weighted" point, it is a fraction of the "doubly weighted" value we compute by introducing that ratio. When computing points on the curve, we compute the "normal" Bézier value and then divide that by the Bézier value for the curve that only uses ratios, not weights.
This does something unexpected: it turns our polynomial into something that isn't a polynomial anymore. It is now a kind of curve that is a super class of the polynomials, and can do some really cool things that Bézier curves can't do "on their own", such as perfectly describing circles (which we'll see in a later section is literally impossible using standard Bézier curves).
But the best way to show what this does is to do literally that: let's look at the effect of "rationalising" our Bézier curves using an interactive graphic for a rationalised curves. The following graphic shows the Bézier curve from the previous section, "enriched" with ratio factors for each coordinate. The closer to zero we set one or more terms, the less relative influence the associated coordinate exerts on the curve (and of course the higher we set them, the more influence they have). Try to change the values and see how it affects what gets drawn:
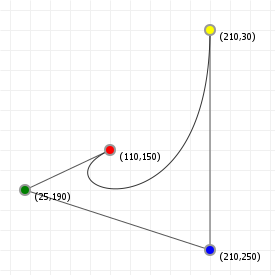
You can think of the ratio values as each coordinate's "gravity": the higher the gravity, the closer to that coordinate the curve will want to be. You'll also notice that if you simply increase or decrease all the ratios by the same amount, nothing changes... much like with gravity, if the relative strengths stay the same, nothing really changes. The values define each coordinate's influence relative to all other points.
How to implement rational curves
Extending the code of the previous section to include ratios is almost trivial:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 | |
| 14 | |
| 15 | |
| 16 | |
| 17 | |
| 18 | |
| 19 | |
| 20 | |
| 21 | |
| 22 | |
| 23 | |
| 24 | |
| 25 | |
| 26 |
And that's all we have to do.
The Bézier interval [0,1]
Now that we know the mathematics behind Bézier curves, there's one curious thing that you may have noticed: they always run from
t=0 to t=1. Why that particular interval?
It all has to do with how we run from "the start" of our curve to "the end" of our curve. If we have a value that is a mixture of two other values, then the general formula for this is:

The obvious start and end values here need to be a=1, b=0, so that the mixed value is 100% value 1, and 0% value 2, and
a=0, b=1, so that the mixed value is 0% value 1 and 100% value 2. Additionally, we don't want "a" and "b" to be independent:
if they are, then we could just pick whatever values we like, and end up with a mixed value that is, for example, 100% value 1
and 100% value 2. In principle that's fine, but for Bézier curves we always want mixed values between the start
and end point, so we need to make sure we can never set "a" and "b" to some values that lead to a mix value that sums to more than 100%.
And that's easy:

With this we can guarantee that we never sum above 100%. By restricting a to values in the interval [0,1], we will always be
somewhere between our two values (inclusively), and we will always sum to a 100% mix.
But... what if we use this form, which is based on the assumption that we will only ever use values between 0 and 1, and instead use values outside of that interval? Do things go horribly wrong? Well... not really, but we get to "see more".
In the case of Bézier curves, extending the interval simply makes our curve "keep going". Bézier curves are simply segments of some polynomial curve, so if we pick a wider interval we simply get to see more of the curve. So what do they look like?
The following two graphics show you Bézier curves rendered "the usual way", as well as the curves they "lie on" if we were to extend the
t values much further. As you can see, there's a lot more "shape" hidden in the rest of the curve, and we can model those
parts by moving the curve points around.

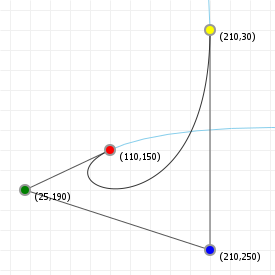
In fact, there are curves used in graphics design and computer modelling that do the opposite of Bézier curves; rather than fixing the interval, and giving you freedom to choose the coordinates, they fix the coordinates, but give you freedom over the interval. A great example of this is the "Spiro" curve, which is a curve based on part of a Cornu Spiral, also known as Euler's Spiral. It's a very aesthetically pleasing curve and you'll find it in quite a few graphics packages like FontForge and Inkscape. It has even been used in font design, for example for the Inconsolata typeface.
Bézier curvatures as matrix operations
We can also represent Bézier curves as matrix operations, by expressing the Bézier formula as a polynomial basis function and a coefficients matrix, and the actual coordinates as a matrix. Let's look at what this means for the cubic curve, using P... to refer to coordinate values "in one or more dimensions":

Disregarding our actual coordinates for a moment, we have:

We can write this as a sum of four expressions:

And we can expand these expressions:

Furthermore, we can make all the 1 and 0 factors explicit:

And that, we can view as a series of four matrix operations:

If we compact this into a single matrix operation, we get:

This kind of polynomial basis representation is generally written with the bases in increasing order, which means we need to flip our
t matrix horizontally, and our big "mixing" matrix upside down:

And then finally, we can add in our original coordinates as a single third matrix:

We can perform the same trick for the quadratic curve, in which case we end up with:

If we plug in a t value, and then multiply the matrices, we will get exactly the same values as when we evaluate the original
polynomial function, or as when we evaluate the curve using progressive linear interpolation.
So: why would we bother with matrices? Matrix representations allow us to discover things about functions that would otherwise be hard to tell. It turns out that the curves form triangular matrices, and they have a determinant equal to the product of the actual coordinates we use for our curve. It's also invertible, which means there's a ton of properties that are all satisfied. Of course, the main question is "why is this useful to us now?", and the answer to that is that it's not immediately useful, but you'll be seeing some instances where certain curve properties can be either computed via function manipulation, or via clever use of matrices, and sometimes the matrix approach can be (drastically) faster.
So for now, just remember that we can represent curves this way, and let's move on.
de Casteljau's algorithm
If we want to draw Bézier curves, we can run through all values of t from 0 to 1 and then compute the weighted basis function
at each value, getting the x/y values we need to plot. Unfortunately, the more complex the curve gets, the more expensive
this computation becomes. Instead, we can use de Casteljau's algorithm to draw curves. This is a geometric approach to curve
drawing, and it's really easy to implement. So easy, in fact, you can do it by hand with a pencil and ruler.
Rather than using our calculus function to find x/y values for t, let's do this instead:
- treat
tas a ratio (which it is). t=0 is 0% along a line, t=1 is 100% along a line. - Take all lines between the curve's defining points. For an order
ncurve, that'snlines. -
Place markers along each of these line, at distance
t. So iftis 0.2, place the mark at 20% from the start, 80% from the end. - Now form lines between
thosepoints. This givesn-1lines. - Place markers along each of these line at distance
t. - Form lines between
thosepoints. This'll ben-2lines. - Place markers, form lines, place markers, etc.
-
Repeat this until you have only one line left. The point
ton that line coincides with the original curve point att.
To see this in action, move the slider for the following sketch to changes which curve point is explicitly evaluated using de Casteljau's algorithm.
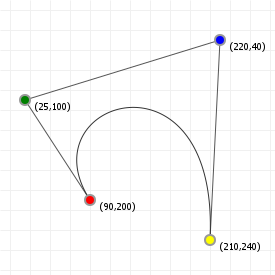
How to implement de Casteljau's algorithm
Let's just use the algorithm we just specified, and implement that as a function that can take a list of curve-defining points, and a
t value, and draws the associated point on the curve for that t value:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 |
And done, that's the algorithm implemented. Although: usually you don't get the luxury of overloading the "+" operator, so let's also
give the code for when you need to work with x and y values separately:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 |
So what does this do? This draws a point, if the passed list of points is only 1 point long. Otherwise it will create a new list of points that sit at the t ratios (i.e. the "markers" outlined in the above algorithm), and then call the draw function for this new list.
Simplified drawing
We can also simplify the drawing process by "sampling" the curve at certain points, and then joining those points up with straight lines, a process known as "flattening", as we are reducing a curve to a simple sequence of straight, "flat" lines.
We can do this is by saying "we want X segments", and then sampling the curve at intervals that are spaced such that we end up with the number of segments we wanted. The advantage of this method is that it's fast: instead of evaluating 100 or even 1000 curve coordinates, we can sample a much lower number and still end up with a curve that sort-of-kind-of looks good enough. The disadvantage of course is that we lose the precision of working with "the real curve", so we usually can't use the flattened for doing true intersection detection, or curvature alignment.
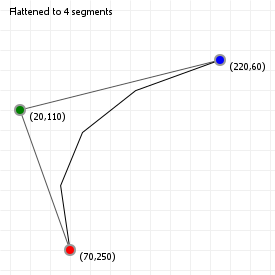
Try clicking on the sketch and using your up and down arrow keys to lower the number of segments for both the quadratic and cubic curve. You'll notice that for certain curvatures, a low number of segments works quite well, but for more complex curvatures (try this for the cubic curve), a higher number is required to capture the curvature changes properly.
How to implement curve flattening
Let's just use the algorithm we just specified, and implement that:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 |
And done, that's the algorithm implemented. That just leaves drawing the resulting "curve" as a sequence of lines:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 |
We start with the first coordinate as reference point, and then just draw lines between each point and its next point.
Splitting curves
Using de Casteljau's algorithm, we can also find all the points we need to split up a Bézier curve into two, smaller curves, which taken
together form the original curve. When we construct de Casteljau's skeleton for some value t, the procedure gives us all the
points we need to split a curve at that t value: one curve is defined by all the inside skeleton points found prior to our
on-curve point, with the other curve being defined by all the inside skeleton points after our on-curve point.
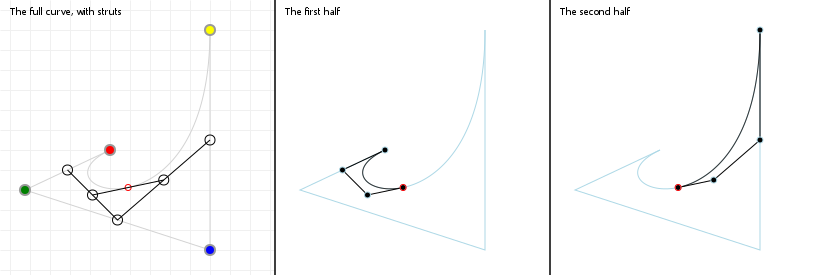
implementing curve splitting
We can implement curve splitting by bolting some extra logging onto the de Casteljau function:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 | |
| 14 | |
| 15 | |
| 16 |
After running this function for some value t, the left and right arrays will contain all the
coordinates for two new curves - one to the "left" of our t value, the other on the "right". These new curves will have the
same order as the original curve, and can be overlaid exactly on the original curve.
Splitting curves using matrices
Another way to split curves is to exploit the matrix representation of a Bézier curve. In the section on matrices, we saw that we can represent curves as matrix multiplications. Specifically, we saw these two forms for the quadratic and cubic curves respectively: (we'll reverse the Bézier coefficients vector for legibility)

and

Let's say we want to split the curve at some point t = z, forming two new (obviously smaller) Bézier curves. To find the
coordinates for these two Bézier curves, we can use the matrix representation and some linear algebra. First, we separate out the actual
"point on the curve" information into a new matrix multiplication:

and

If we could compact these matrices back to the form [t values] · [Bézier matrix] · [column matrix], with the first two
staying the same, then that column matrix on the right would be the coordinates of a new Bézier curve that describes the first segment,
from t = 0 to t = z. As it turns out, we can do this quite easily, by exploiting some simple rules of linear
algebra (and if you don't care about the derivations, just skip to the end of the box for the results!).
Deriving new hull coordinates
Deriving the two segments upon splitting a curve takes a few steps, and the higher the curve order, the more work it is, so let's look at the quadratic curve first:




We can do this because [M · M-1] is the identity matrix. It's a bit like multiplying something by x/x in calculus: it doesn't do anything to the function, but it does allow you to rewrite it to something that may be easier to work with, or can be broken up differently. In the same way, multiplying our matrix by [M · M-1] has no effect on the total formula, but it does allow us to change the matrix sequence [something · M] to a sequence [M · something], and that makes a world of difference: if we know what [M-1 · Z · M] is, we can apply that to our coordinates, and be left with a proper matrix representation of a quadratic Bézier curve (which is [T · M · P]), with a new set of coordinates that represent the curve from t = 0 to t = z. So let's get computing:

Excellent! Now we can form our new quadratic curve:



Brilliant: if we want a subcurve from t = 0 to t = z, we can keep the first coordinate the
same (which makes sense), our control point becomes a z-ratio mixture of the original control point and the start point, and the new end
point is a mixture that looks oddly similar to a
Bernstein polynomial of degree two. These new coordinates are actually
really easy to compute directly!
Of course, that's only one of the two curves. Getting the section from t = z to t = 1 requires doing this
again. We first observe that in the previous calculation, we actually evaluated the general interval [0,z]. We were able to
write it down in a more simple form because of the zero, but what we actually evaluated, making the zero explicit, was:


If we want the interval [z,1], we will be evaluating this instead:


We're going to do the same trick of multiplying by the identity matrix, to turn [something · M] into
[M · something]:

So, our final second curve looks like:



Nice. We see the same thing as before: we can keep the last coordinate the same (which makes sense); our control point becomes a z-ratio mixture of the original control point and the end point, and the new start point is a mixture that looks oddly similar to a bernstein polynomial of degree two, except this time it uses (z-1) rather than (1-z). These new coordinates are also really easy to compute directly!
So, using linear algebra rather than de Casteljau's algorithm, we have determined that, for any quadratic curve split at some value
t = z, we get two subcurves that are described as Bézier curves with simple-to-derive coordinates:

and

We can do the same for cubic curves. However, I'll spare you the actual derivation (don't let that stop you from writing that out yourself, though) and simply show you the resulting new coordinate sets:

and

So, looking at our matrices, did we really need to compute the second segment matrix? No, we didn't. Actually having one segment's matrix means we implicitly have the other: push the values of each row in the matrix Q to the right, with zeroes getting pushed off the right edge and appearing back on the left, and then flip the matrix vertically. Presto, you just "calculated" Q'.
Implementing curve splitting this way requires less recursion, and is just straight arithmetic with cached values, so can be cheaper on systems where recursion is expensive. If you're doing computation with devices that are good at matrix multiplication, chopping up a Bézier curve with this method will be a lot faster than applying de Casteljau.
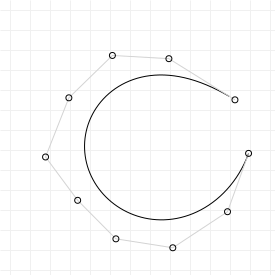
Lowering and elevating curve order
One interesting property of Bézier curves is that an nth order curve can always be perfectly represented by an (n+1)th order curve, by giving the higher-order curve specific control points.
If we have a curve with three points, then we can create a curve with four points that exactly reproduces the original curve. First, we give it the same start and end points, and for its two control points we pick "1/3rd start + 2/3rd control" and "2/3rd control + 1/3rd end". Now we have exactly the same curve as before, except represented as a cubic curve rather than a quadratic curve.
The general rule for raising an nth order curve to an (n+1)th order curve is as follows (observing that the start and end weights are the same as the start and end weights for the old curve):

However, this rule also has as direct consequence that you cannot generally safely lower a curve from nth order to (n-1)th order, because the control points cannot be "pulled apart" cleanly. We can try to, but the resulting curve will not be identical to the original, and may in fact look completely different.
However, there is a surprisingly good way to ensure that a lower order curve looks "as close as reasonably possible" to the original curve: we can optimise the "least-squares distance" between the original curve and the lower order curve, in a single operation (also explained over on Sirver's Castle). However, to use it, we'll need to do some calculus work and then switch over to linear algebra. As mentioned in the section on matrix representations, some things can be done much more easily with matrices than with calculus functions, and this is one of those things. So... let's go!
We start by taking the standard Bézier function, and condensing it a little:

Then, we apply one of those silly (actually, super useful) calculus tricks: since our t value is always between zero and one
(inclusive), we know that (1-t) plus t always sums to 1. As such, we can express any value as a sum of
t and 1-t:

So, with that seemingly trivial observation, we rewrite that Bézier function by splitting it up into a sum of a (1-t) and
t component:

So far so good. Now, to see why we did this, let's write out the (1-t) and t parts, and see what that gives us.
I promise, it's about to make sense. We start with (1-t):

So by using this seemingly silly trick, we can suddenly express part of our nth order Bézier function in terms of an (n+1)th
order Bézier function. And that sounds a lot like raising the curve order! Of course we need to be able to repeat that trick for the
t part, but that's not a problem:

So, with both of those changed from an order n expression to an order (n+1) expression, we can put them back
together again. Now, where the order n function had a summation from 0 to n, the order n+1 function
uses a summation from 0 to n+1, but this shouldn't be a problem as long as we can add some new terms that "contribute
nothing". In the next section on derivatives, there is a discussion about why "higher terms than there is a binomial for" and "lower than
zero terms" both "contribute nothing". So as long as we can add terms that have the same form as the terms we need, we can just include
them in the summation, they'll sit there and do nothing, and the resulting function stays identical to the lower order curve.
Let's do this:

And this is where we switch over from calculus to linear algebra, and matrices: we can now express this relation between Bézier(n,t) and Bézier(n+1,t) as a very simple matrix multiplication:

where the matrix M is an n+1 by n matrix, and looks like:

That might look unwieldy, but it's really just a mostly-zeroes matrix, with a very simply fraction on the diagonal, and an even simpler fraction to the left of it. Multiplying a list of coordinates with this matrix means we can plug the resulting transformed coordinates into the one-order-higher function and get an identical looking curve.
Not too bad!
Equally interesting, though, is that with this matrix operation established, we can now use an incredibly powerful and ridiculously simple way to find out a "best fit" way to reverse the operation, called the normal equation. What it does is minimize the sum of the square differences between one set of values and another set of values. Specifically, if we can express that as some function A x = b, we can use it. And as it so happens, that's exactly what we're dealing with, so:

The steps taken here are:
- We have a function in a form that the normal equation can be used with, so
- apply the normal equation!
- Then, we want to end up with just Bn on the left, so we start by left-multiply both sides such that we'll end up with lots of stuff on the left that simplified to "a factor 1", which in matrix maths is the identity matrix.
- In fact, by left-multiplying with the inverse of what was already there, we've effectively "nullified" (but really, one-inified) that big, unwieldy block into the identity matrix I. So we substitute the mess with I, and then
- because multiplication with the identity matrix does nothing (like multiplying by 1 does nothing in regular algebra), we just drop it.
And we're done: we now have an expression that lets us approximate an n+1th order curve with a lower nth order curve. It won't be an exact fit, but it's definitely a best approximation. So, let's implement these rules for
raising and lowering curve order to a (semi) random curve, using the following graphic. Select the sketch, which has movable control
points, and press your up and down arrow keys to raise or lower the curve order.
Derivatives
There's a number of useful things that you can do with Bézier curves based on their derivative, and one of the more amusing observations about Bézier curves is that their derivatives are, in fact, also Bézier curves. In fact, the differentiation of a Bézier curve is relatively straightforward, although we do need a bit of math.
First, let's look at the derivative rule for Bézier curves, which is:

which we can also write (observing that b in this formula is the same as our w weights, and that n times a summation is the same as a summation where each term is multiplied by n) as:

Or, in plain text: the derivative of an nth degree Bézier curve is an (n-1)th degree Bézier curve, with one fewer term, and new weights w'0...w'n-1 derived from the original weights as n(wi+1 - wi). So for a 3rd degree curve, with four weights, the derivative has three new weights: w'0 = 3(w1-w0), w'1 = 3(w2-w1) and w'2 = 3(w3-w2).
"Slow down, why is that true?"
Sometimes just being told "this is the derivative" is nice, but you might want to see why this is indeed the case. As such, let's have a look at the proof for this derivative. First off, the weights are independent of the full Bézier function, so the derivative involves only the derivative of the polynomial basis function. So, let's find that:

Applying the product and chain rules gives us:

Which is hard to work with, so let's expand that properly:

Now, the trick is to turn this expression into something that has binomial coefficients again, so we want to end up with things that look like "x! over y!(x-y)!". If we can do that in a way that involves terms of n-1 and k-1, we'll be on the right track.

And that's the first part done: the two components inside the parentheses are actually regular, lower-order Bézier expressions:

Now to apply this to our weighted Bézier curves. We'll write out the plain curve formula that we saw earlier, and then work our way through to its derivative:

If we expand this (with some color to show how terms line up), and reorder the terms by increasing values for k we see the following:

Two of these terms fall way: the first term falls away because there is no -1st term in a summation. As such, it always contributes "nothing", so we can safely completely ignore it for the purpose of finding the derivative function. The other term is the very last term in this expansion: one involving Bn-1,n. This term would have a binomial coefficient of [i choose i+1], which is a non-existent binomial coefficient. Again, this term would contribute "nothing", so we can ignore it, too. This means we're left with:

And that's just a summation of lower order curves:

We can rewrite this as a normal summation, and we're done:

Let's rewrite that in a form similar to our original formula, so we can see the difference. We will first list our original formula for Bézier curves, and then the derivative:


What are the differences? In terms of the actual Bézier curve, virtually nothing! We lowered the order (rather than n, it's now n-1), but it's still the same Bézier function. The only real difference is in how the weights change when we derive the curve's function. If we have four points A, B, C, and D, then the derivative will have three points, the second derivative two, and the third derivative one:

We can keep performing this trick for as long as we have more than one weight. Once we have one weight left, the next step will see k = 0, and the result of our "Bézier function" summation is zero, because we're not adding anything at all. As such, a quadratic curve has no second derivative, a cubic curve has no third derivative, and generalized: an nth order curve has n-1 (meaningful) derivatives, with any further derivative being zero.
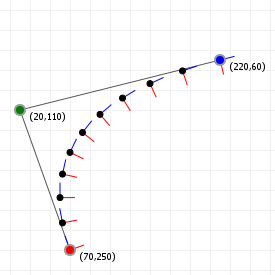
Tangents and normals
If you want to move objects along a curve, or "away from" a curve, the two vectors you're most interested in are the tangent vector and normal vector for curve points. These are actually really easy to find. For moving and orienting along a curve, we use the tangent, which indicates the direction of travel at specific points, and is literally just the first derivative of our curve:

This gives us the directional vector we want. We can normalize it to give us uniform directional vectors (having a length of 1.0) at each point, and then do whatever it is we want to do based on those directions:

The tangent is very useful for moving along a line, but what if we want to move away from the curve instead, perpendicular to the curve at some point t? In that case we want the normal vector. This vector runs at a right angle to the direction of the curve, and is typically of length 1.0, so all we have to do is rotate the normalized directional vector and we're done:

Rotating coordinates is actually very easy, if you know the rule for it. You might find it explained as "applying a rotation matrix, which is what we'll look at here, too. Essentially, the idea is to take the circles over which we can rotate, and simply "sliding the coordinates" over these circles by the desired angle. If we want a quarter circle turn, we take the coordinate, slide it along the circle by a quarter turn, and done.
To turn any point (x,y) into a rotated point (x',y') (over 0,0) by some angle φ, we apply this nice and easy computation:

Which is the "long" version of the following matrix transformation:

And that's all we need to rotate any coordinate. Note that for quarter, half, and three-quarter turns these functions become even easier, since sin and cos for these angles are, respectively: 0 and 1, -1 and 0, and 0 and -1.
But why does this work? Why this matrix multiplication? Wikipedia (technically, Thomas Herter and Klaus Lott) tells us that a rotation matrix can be treated as a sequence of three (elementary) shear operations. When we combine this into a single matrix operation (because all matrix multiplications can be collapsed), we get the matrix that you see above. DataGenetics have an excellent article about this very thing: it's really quite cool, and I strongly recommend taking a quick break from this primer to read that article.
The following two graphics show the tangent and normal along a quadratic and cubic curve, with the direction vector coloured blue, and the normal vector coloured red (the markers are spaced out evenly as t-intervals, not spaced equidistant).
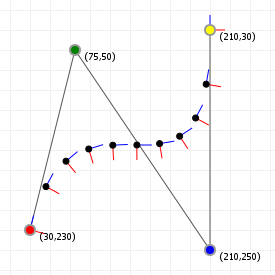
Working with 3D normals
Before we move on to the next section we need to spend a little bit of time on the difference between 2D and 3D. While for many things this difference is irrelevant and the procedures are identical (for instance, getting the 3D tangent is just doing what we do for 2D, but for x, y, and z, instead of just for x and y), when it comes to normals things are a little more complex, and thus more work. Mind you, it's not "super hard", but there are more steps involved and we should have a look at those.
Getting normals in 3D is in principle the same as in 2D: we take the normalised tangent vector, and then rotate it by a quarter turn. However, this is where things get that little more complex: we can turn in quite a few directions, since "the normal" in 3D is a plane, not a single vector, so we basically need to define what "the" normal is in the 3D case.
The "naïve" approach is to construct what is known as the Frenet normal, where we follow a simple recipe that works in many cases (but does super bizarre things in some others). The idea is that even though there are infinitely many vectors that are perpendicular to the tangent (i.e. make a 90 degree angle with it), the tangent itself sort of lies on its own plane already: since each point on the curve (no matter how closely spaced) has its own tangent vector, we can say that each point lies in the same plane as the local tangent, as well as the tangents "right next to it".
Even if that difference in tangent vectors is minute, "any difference" is all we need to find out what that plane is - or rather, what the vector perpendicular to that plane is. Which is what we need: if we can calculate that vector, and we have the tangent vector that we know lies on a plane, then we can rotate the tangent vector over the perpendicular, and presto. We have computed the normal using the same logic we used for the 2D case: "just rotate it 90 degrees".
So let's do that! And in a twist surprise, we can do this in four lines:
- a = normalize(B'(t))
- b = normalize(a + B''(t))
- r = normalize(b × a)
- normal = normalize(r × a)
Let's unpack that a little:
- We start by taking the normalized vector for the derivative at some point on the curve. We normalize it so the maths is less work. Less work is good.
- Then, we compute b which represents what a next point's tangent would be if the curve stopped changing at our point and just had the same derivative and second derivative from that point on.
- This lets us find two vectors (the derivative, and the second derivative added to the derivative) that lie on the same plane, which means we can use them to compute a vector perpendicular to that plane, using an elementary vector operation called the cross product. (Note that while that operation uses the × operator, it's most definitely not a multiplication!) The result of that gives us a vector that we can use as the "axis of rotation" for turning the tangent a quarter circle to get our normal, just like we did in the 2D case.
- Since the cross product lets us find a vector that is perpendicular to some plane defined by two other vectors, and since the normal vector should be perpendicular to the plane that the tangent and the axis of rotation lie in, we can use the cross product a second time, and immediately get our normal vector.
And then we're done, we found "the" normal vector for a 3D curve. Let's see what that looks like for a sample curve, shall we? You can move your cursor across the graphic from left to right, to show the normal at a point with a t value that is based on your cursor position: all the way on the left is 0, all the way on the right = 1, midway is t=0.5, etc:
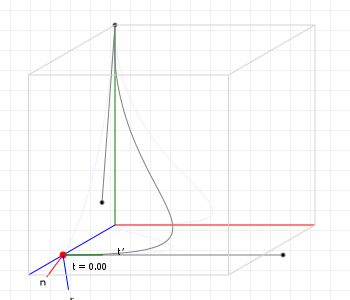
However, if you've played with that graphic a bit, you might have noticed something odd. The normal seems to "suddenly twist around the curve" between t=0.65 and t=0.75... Why is it doing that?
As it turns out, it's doing that because that's how the maths works, and that's the problem with Frenet normals: while they are "mathematically correct", they are "practically problematic", and so for any kind of graphics work what we really want is a way to compute normals that just... look good.
Thankfully, Frenet normals are not our only option.
Another option is to take a slightly more algorithmic approach and compute a form of Rotation Minimising Frame (also known as "parallel transport frame" or "Bishop frame") instead, where a "frame" is a set made up of the tangent, the rotational axis, and the normal vector, centered on an on-curve point.
These type of frames are computed based on "the previous frame", so we cannot simply compute these "on demand" for single points, as we could for Frenet frames; we have to compute them for the entire curve. Thankfully, the procedure is pretty simple, and can be performed at the same time that you're building lookup tables for your curve.
The idea is to take a starting "tangent/rotation axis/normal" frame at t=0, and then compute what the next frame "should" look like by applying some rules that yield a good looking next frame. In the case of the RMF paper linked above, those rules are:
- Take a point on the curve for which we know the RM frame already,
- take a next point on the curve for which we don't know the RM frame yet, and
- reflect the known frame onto the next point, by treating the plane through the curve at the point exactly between the next and previous points as a "mirror".
- This gives the next point a tangent vector that's essentially pointing in the opposite direction of what it should be, and a normal that's slightly off-kilter, so:
- reflect the vectors of our "mirrored frame" a second time, but this time using the plane through the "next point" itself as "mirror".
- Done: the tangent and normal have been fixed, and we have a good looking frame to work with.
So, let's write some code for that!
Implementing Rotation Minimising Frames
We first assume we have a function for calculating the Frenet frame at a point, which we already discussed above, inn a way that it yields a frame with properties:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 |
Then, we can write a function that generates a sequence of RM frames in the following manner:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 | |
| 14 | |
| 15 | |
| 16 | |
| 17 | |
| 18 | |
| 19 | |
| 20 | |
| 21 | |
| 22 | |
| 23 | |
| 24 | |
| 25 | |
| 26 | |
| 27 | |
| 28 | |
| 29 | |
| 30 | |
| 31 | |
| 32 | |
| 33 | |
| 34 | |
| 35 | |
| 36 |
Ignoring comments, this is certainly more code than when we were just computing a single Frenet frame, but it's not a crazy amount more code to get much better looking normals.
Speaking of better looking, what does this actually look like? Let's revisit that earlier curve, but this time use rotation minimising frames rather than Frenet frames:
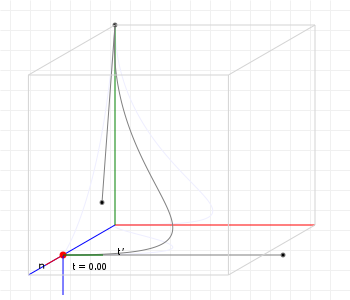
That looks so much better!
For those reading along with the code: we don't even strictly speaking need a Frenet frame to start with: we could, for instance, treat the z-axis as our initial axis of rotation, so that our initial normal is (0,0,1) × tangent, and then take things from there, but having that initial "mathematically correct" frame so that the initial normal seems to line up based on the curve's orientation in 3D space is just nice.
Component functions
One of the first things people run into when they start using Bézier curves in their own programs is "I know how to draw the curve, but how do I determine the bounding box?". It's actually reasonably straightforward to do so, but it requires having some knowledge on exploiting math to get the values we need. For bounding boxes, we aren't actually interested in the curve itself, but only in its "extremities": the minimum and maximum values the curve has for its x- and y-axis values. If you remember your calculus (provided you ever took calculus, otherwise it's going to be hard to remember) we can determine function extremities using the first derivative of that function, but this poses a problem, since our function is parametric: every axis has its own function.
The solution: compute the derivative for each axis separately, and then fit them back together in the same way we do for the original.
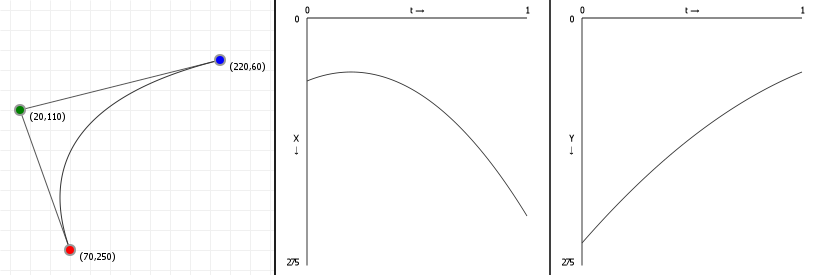
Let's look at how a parametric Bézier curve "splits up" into two normal functions, one for the x-axis and one for the y-axis. Note the leftmost figure is again an interactive curve, without labeled axes (you get coordinates in the graph instead). The center and rightmost figures are the component functions for computing the x-axis value, given a value for t (between 0 and 1 inclusive), and the y-axis value, respectively.
If you move points in a curve sideways, you should only see the middle graph change; likewise, moving points vertically should only show a change in the right graph.
Finding extremities: root finding
Now that we understand (well, superficially anyway) the component functions, we can find the extremities of our Bézier curve by finding maxima and minima on the component functions, by solving the equation B'(t) = 0. We've already seen that the derivative of a Bézier curve is a simpler Bézier curve, but how do we solve the equality? Fairly easily, actually, until our derivatives are 4th order or higher... then things get really hard. But let's start simple:
Quadratic curves: linear derivatives.
The derivative of a quadratic Bézier curve is a linear Bézier curve, interpolating between just two terms, which means finding the
solution for "where is this line 0" is effectively trivial by rewriting it to a function of t and solving. First we turn our
quadratic Bézier function into a linear one, by following the rule mentioned at the end of the
derivatives section:

And then we turn this into our solution for t using basic arithmetics:

Done.
Although with the caveat that if b-a is zero, there
is no solution and we probably shouldn't try to perform that division.
Cubic curves: the quadratic formula.
The derivative of a cubic Bézier curve is a quadratic Bézier curve, and finding the roots for a quadratic polynomial means we can apply the Quadratic formula. If you've seen it before, you'll remember it, and if you haven't, it looks like this:

So, if we can rewrite the Bézier component function as a plain polynomial, we're done: we just plug in the values into the quadratic formula, check if that square root is negative or not (if it is, there are no roots) and then just compute the two values that come out (because of that plus/minus sign we get two). Any value between 0 and 1 is a root that matters for Bézier curves, anything below or above that is irrelevant (because Bézier curves are only defined over the interval [0,1]). So, how do we convert?
First we turn our cubic Bézier function into a quadratic one, by following the rule mentioned at the end of the derivatives section:

And then, using these v values, we can find out what our a, b, and c should be:

This gives us three coefficients {a, b, c} that are expressed in terms of v values, where the v values are
expressions of our original coordinate values, so we can do some substitution to get:

Easy-peasy. We can now almost trivially find the roots by plugging those values into the quadratic formula.
And as a cubic curve, there is also a meaningful second derivative, which we can compute by simple taking the derivative of the derivative.
Quartic curves: Cardano's algorithm.
We haven't really looked at them before now, but the next step up would be a Quartic curve, a fourth degree Bézier curve. As expected, these have a derivative that is a cubic function, and now things get much harder. Cubic functions don't have a "simple" rule to find their roots, like the quadratic formula, and instead require quite a bit of rewriting to a form that we can even start to try to solve.
Back in the 16th century, before Bézier curves were a thing, and even before calculus itself was a thing, Gerolamo Cardano figured out that even if the general cubic function is really hard to solve, it can be rewritten to a form for which finding the roots is "easier" (even if not "easy"):

We can see that the easier formula only has two constants, rather than four, and only two expressions involving t, rather
than three: this makes things considerably easier to solve because it lets us use
regular calculus to find the values that satisfy the equation.
Now, there is one small hitch: as a cubic function, the solutions may be complex numbers rather than plain numbers... And Cardano realised this, centuries before complex numbers were a well-understood and established part of number theory. His interpretation of them was "these numbers are impossible but that's okay because they disappear again in later steps", allowing him to not think about them too much, but we have it even easier: as we're trying to find the roots for display purposes, we don't even care about complex numbers: we're going to simplify Cardano's approach just that tiny bit further by throwing away any solution that's not a plain number.
So, how do we rewrite the hard formula into the easier formula? This is explained in detail over at Ken J. Ward's page for solving the cubic equation, so instead of showing the maths, I'm simply going to show the programming code for solving the cubic equation, with the complex roots getting totally ignored, but if you're interested you should definitely head over to Ken's page and give the procedure a read-through.
Implementing Cardano's algorithm for finding all real roots
The "real roots" part is fairly important, because while you cannot take a square, cube, etc. root of a negative number in the "real" number space (denoted with ℝ), this is perfectly fine in the "complex" number space (denoted with ℂ). And, as it so happens, Cardano is also attributed as the first mathematician in history to have made use of complex numbers in his calculations. For this very algorithm!
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 | |
| 14 | |
| 15 | |
| 16 | |
| 17 | |
| 18 | |
| 19 | |
| 20 | |
| 21 | |
| 22 | |
| 23 | |
| 24 | |
| 25 | |
| 26 | |
| 27 | |
| 28 | |
| 29 | |
| 30 | |
| 31 | |
| 32 | |
| 33 | |
| 34 | |
| 35 | |
| 36 | |
| 37 | |
| 38 | |
| 39 | |
| 40 | |
| 41 | |
| 42 | |
| 43 | |
| 44 | |
| 45 | |
| 46 | |
| 47 | |
| 48 | |
| 49 | |
| 50 | |
| 51 | |
| 52 | |
| 53 | |
| 54 | |
| 55 | |
| 56 | |
| 57 | |
| 58 | |
| 59 | |
| 60 | |
| 61 | |
| 62 | |
| 63 | |
| 64 | |
| 65 | |
| 66 | |
| 67 | |
| 68 | |
| 69 | |
| 70 | |
| 71 | |
| 72 | |
| 73 | |
| 74 | |
| 75 | |
| 76 | |
| 77 | |
| 78 | |
| 79 | |
| 80 | |
| 81 |
And that's it. The maths is complicated, but the code is pretty much just "follow the maths, while caching as many values as we can to prevent recomputing things as much as possible" and now we have a way to find all roots for a cubic function and can just move on with using that to find extremities of our curves.
And of course, as a quartic curve also has meaningful second and third derivatives, we can quite easily compute those by using the derivative of the derivative (of the derivative), just as for cubic curves.
Quintic and higher order curves: finding numerical solutions
And this is where thing stop, because we cannot find the roots for polynomials of degree 5 or higher using algebra (a fact known as the Abel–Ruffini theorem). Instead, for occasions like these, where algebra simply cannot yield an answer, we turn to numerical analysis.
That's a fancy term for saying "rather than trying to find exact answers by manipulating symbols, find approximate answers by describing the underlying process as a combination of steps, each of which can be assigned a number via symbolic manipulation". For example, trying to mathematically compute how much water fits in a completely crazy three dimensional shape is very hard, even if it got you the perfect, precise answer. A much easier approach, which would be less perfect but still entirely useful, would be to just grab a buck and start filling the shape until it was full: just count the number of buckets of water you used. And if we want a more precise answer, we can use smaller buckets.
So that's what we're going to do here, too: we're going to treat the problem as a sequence of steps, and the smaller we can make each
step, the closer we'll get to that "perfect, precise" answer. And as it turns out, there is a really nice numerical root-finding
algorithm, called the Newton-Raphson root finding method (yes, after
that Newton), which we can make use of. The Newton-Raphson approach
consists of taking our impossible-to-solve function f(x), picking some initial value x (literally any value will
do), and calculating f(x). We can think of that value as the "height" of the function at x. If that height is
zero, we're done, we have found a root. If it isn't, we calculate the tangent line at f(x) and calculate at which
x value its height is zero (which we've already seen is very easy). That will give us a new x and we
repeat the process until we find a root.
Mathematically, this means that for some x, at step n=1, we perform the following calculation until
fy(x) is zero, so that the next t is the same as the one we already have:

(The Wikipedia article has a decent animation for this process, so I will not add a graphic for that here)
Now, this works well only if we can pick good starting points, and our curve is continuously differentiable and doesn't have oscillations. Glossing over the exact meaning of those terms, the curves we're dealing with conform to those constraints, so as long as we pick good starting points, this will work. So the question is: which starting points do we pick?
As it turns out, Newton-Raphson is so blindingly fast that we could get away with just not picking: we simply run the algorithm from t=0 to t=1 at small steps (say, 1/200th) and the result will be all the roots we want. Of course, this may pose problems for high order Bézier curves: 200 steps for a 200th order Bézier curve is going to go wrong, but that's okay: there is no reason (at least, none that I know of) to ever use Bézier curves of crazy high orders. You might use a fifth order curve to get the "nicest still remotely workable" approximation of a full circle with a single Bézier curve, but that's pretty much as high as you'll ever need to go.
In conclusion:
So now that we know how to do root finding, we can determine the first and second derivative roots for our Bézier curves, and show those roots overlaid on the previous graphics. For the quadratic curve, that means just the first derivative, in red:
And for cubic curves, that means first and second derivatives, in red and purple respectively:
Bounding boxes
If we have the extremities, and the start/end points, a simple for-loop that tests for min/max values for x and y means we have the four values we need to box in our curve:
Computing the bounding box for a Bézier curve:
- Find all t value(s) for the curve derivative's x- and y-roots.
- Discard any t value that's lower than 0 or higher than 1, because Bézier curves only use the interval [0,1].
- Determine the lowest and highest value when plugging the values t=0, t=1 and each of the found roots into the original functions: the lowest value is the lower bound, and the highest value is the upper bound for the bounding box we want to construct.
Applying this approach to our previous root finding, we get the following axis-aligned bounding boxes (with all curve extremity points shown on the curve):
We can construct even nicer boxes by aligning them along our curve, rather than along the x- and y-axis, but in order to do so we first need to look at how aligning works.
Aligning curves
While there are an incredible number of curves we can define by varying the x- and y-coordinates for the control points, not all curves are actually distinct. For instance, if we define a curve, and then rotate it 90 degrees, it's still the same curve, and we'll find its extremities in the same spots, just at different draw coordinates. As such, one way to make sure we're working with a "unique" curve is to "axis-align" it.
Aligning also simplifies a curve's functions. We can translate (move) the curve so that the first point lies on (0,0), which turns our n term polynomial functions into n-1 term functions. The order stays the same, but we have less terms. Then, we can rotate the curves so that the last point always lies on the x-axis, too, making its coordinate (...,0). This further simplifies the function for the y-component to an n-2 term function. For instance, if we have a cubic curve such as this:

Then translating it so that the first coordinate lies on (0,0), moving all x coordinates by -120, and all y coordinates by -160, gives us:

If we then rotate the curve so that its end point lies on the x-axis, the coordinates (integer-rounded for illustrative purposes here) become:

If we drop all the zero-terms, this gives us:

We can see that our original curve definition has been simplified considerably. The following graphics illustrate the result of aligning our example curves to the x-axis, with the cubic case using the coordinates that were just used in the example formulae:
Tight bounding boxes
With our knowledge of bounding boxes, and curve alignment, We can now form the "tight" bounding box for curves. We first align our curve, recording the translation we performed, "T", and the rotation angle we used, "R". We then determine the aligned curve's normal bounding box. Once we have that, we can map that bounding box back to our original curve by rotating it by -R, and then translating it by -T.
We now have nice tight bounding boxes for our curves:
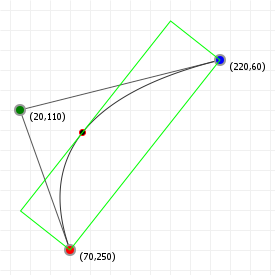
These are, strictly speaking, not necessarily the tightest possible bounding boxes. It is possible to compute the optimal bounding box by determining which spanning lines we need to effect a minimal box area, but because of the parametric nature of Bézier curves this is actually a rather costly operation, and the gain in bounding precision is often not worth it.
Curve inflections
Now that we know how to align a curve, there's one more thing we can calculate: inflection points. Imagine we have a variable size circle that we can slide up against our curve. We place it against the curve and adjust its radius so that where it touches the curve, the curvatures of the curve and the circle are the same, and then we start to slide the circle along the curve - for quadratic curves, we can always do this without the circle behaving oddly: we might have to change the radius of the circle as we slide it along, but it'll always sit against the same side of the curve.
But what happens with cubic curves? Imagine we have an S curve and we place our circle at the start of the curve, and start sliding it along. For a while we can simply adjust the radius and things will be fine, but once we get to the midpoint of that S, something odd happens: the circle "flips" from one side of the curve to the other side, in order for the curvatures to keep matching. This is called an inflection, and we can find out where those happen relatively easily.
What we need to do is solve a simple equation:

What we're saying here is that given the curvature function C(t), we want to know for which values of t this function is zero, meaning there is no "curvature", which will be exactly at the point between our circle being on one side of the curve, and our circle being on the other side of the curve. So what does C(t) look like? Actually something that seems not too hard:

The function C(t) is the cross product between the first and second derivative functions for the parametric dimensions of our curve. And, as already shown, derivatives of Bézier curves are just simpler Bézier curves, with very easy to compute new coefficients, so this should be pretty easy.
However as we've seen in the section on aligning, aligning lets us simplify things a lot, by completely removing the contributions of the first coordinate from most mathematical evaluations, and removing the last y coordinate as well by virtue of the last point lying on the x-axis. So, while we can evaluate C(t) = 0 for our curve, it'll be much easier to first axis-align the curve and then evaluating the curvature function.
Let's derive the full formula anyway
Of course, before we do our aligned check, let's see what happens if we compute the curvature function without axis-aligning. We start with the first and second derivatives, given our basis functions:

And of course the same functions for y:

Asking a computer to now compose the C(t) function for us (and to expand it to a readable form of simple terms) gives us this rather overly complicated set of arithmetic expressions:

That is... unwieldy. So, we note that there are a lot of terms that involve multiplications involving x1, y1, and y4, which would all disappear if we axis-align our curve, which is why aligning is a great idea.
Aligning our curve so that three of the eight coefficients become zero, and observing that scale does not affect finding
t values, we end up with the following simple term function for C(t):

That's a lot easier to work with: we see a fair number of terms that we can compute and then cache, giving us the following simplification:

This is a plain quadratic curve, and we know how to solve C(t) = 0; we use the quadratic formula:

We can easily compute this value if the discriminator isn't a negative number (because we only want real roots, not complex roots), and if x is not zero, because divisions by zero are rather useless.
Taking that into account, we compute t, we disregard any t value that isn't in the Bézier interval [0,1], and we now know at which t value(s) our curve will inflect.
The canonical form (for cubic curves)
While quadratic curves are relatively simple curves to analyze, the same cannot be said of the cubic curve. As a curvature is controlled by more than one control point, it exhibits all kinds of features like loops, cusps, odd colinear features, and as many as two inflection points because the curvature can change direction up to three times. Now, knowing what kind of curve we're dealing with means that some algorithms can be run more efficiently than if we have to implement them as generic solvers, so is there a way to determine the curve type without lots of work?
As it so happens, the answer is yes, and the solution we're going to look at was presented by Maureen C. Stone from Xerox PARC and Tony D. deRose from the University of Washington in their joint paper "A Geometric Characterization of Parametric Cubic curves". It was published in 1989, and defines curves as having a "canonical" form (i.e. a form that all curves can be reduced to) from which we can immediately tell what features a curve will have. So how does it work?
The first observation that makes things work is that if we have a cubic curve with four points, we can apply a linear transformation to these points such that three of the points end up on (0,0), (0,1) and (1,1), with the last point then being "somewhere". After applying that transformation, the location of that last point can then tell us what kind of curve we're dealing with. Specifically, we see the following breakdown:
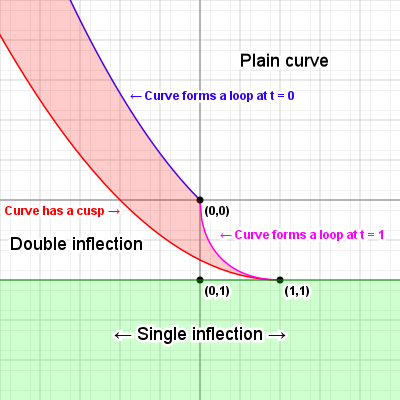
This is a fairly funky image, so let's see what the various parts of it mean...
We see the three fixed points at (0,0), (0,1) and (1,1). The various regions and boundaries indicate what property the original curve will have, if the fourth point is in/on that region or boundary. Specifically, if the fourth point is...
-
...anywhere inside the red zone, but not on its boundaries, the curve will be self-intersecting (yielding a loop). We won't know where it self-intersects (in terms of t values), but we are guaranteed that it does.
-
...on the left (red) edge of the red zone, the curve will have a cusp. We again don't know where, but we know there is one. This edge is described by the function:

-
...on the almost circular, lower right (pink) edge, the curve's end point touches the curve, forming a loop. This edge is described by the function:

-
...on the top (blue) edge, the curve's start point touches the curve, forming a loop. This edge is described by the function:

-
...inside the lower (green) zone, past
y=1, the curve will have a single inflection (switching concave/convex once). -
...between the left and lower boundaries (below the cusp line but above the single-inflection line), the curve will have two inflections (switching from concave to convex and then back again, or from convex to concave and then back again).
...anywhere on the right of self-intersection zone, the curve will have no inflections. It'll just be a simple arch.
Of course, this map is fairly small, but the regions extend to infinity, with well defined boundaries.
Wait, where do those lines come from?
Without repeating the paper mentioned at the top of this section, the loop-boundaries come from rewriting the curve into canonical form, and then solving the formulae for which constraints must hold for which possible curve properties. In the paper these functions yield formulae for where you will find cusp points, or loops where we know t=0 or t=1, but those functions are derived for the full cubic expression, meaning they apply to t=-∞ to t=∞... For Bézier curves we only care about the "clipped interval" t=0 to t=1, so some of the properties that apply when you look at the curve over an infinite interval simply don't apply to the Bézier curve interval.
The right bound for the loop region, indicating where the curve switches from "having inflections" to "having a loop", for the general cubic curve, is actually mirrored over x=1, but for Bézier curves this right half doesn't apply, so we don't need to pay attention to it. Similarly, the boundaries for t=0 and t=1 loops are also nice clean curves but get "cut off" when we only look at what the general curve does over the interval t=0 to t=1.
For the full details, head over to the paper and read through sections 3 and 4. If you still remember your high school pre-calculus, you can probably follow along with this paper, although you might have to read it a few times before all the bits "click".
So now the question becomes: how do we manipulate our curve so that it fits this canonical form, with three fixed points, and one "free" point? Enter linear algebra. Don't worry, I'll be doing all the math for you, as well as show you what the effect is on our curves, but basically we're going to be using linear algebra, rather than calculus, because "it's way easier". Sometimes a calculus approach is very hard to work with, when the equivalent geometrical solution is super obvious.
The approach is going to start with a curve that doesn't have all-colinear points (so we need to make sure the points don't all fall on a straight line), and then applying three graphics operations that you will probably have heard of: translation (moving all points by some fixed x- and y-distance), scaling (multiplying all points by some x and y scale factor), and shearing (an operation that turns rectangles into parallelograms).
Step 1: we translate any curve by -p1.x and -p1.y, so that the curve starts at (0,0). We're going to make use of an interesting trick here, by pretending our 2D coordinates are 3D, with the z coordinate simply always being 1. This is an old trick in graphics to overcome the limitations of 2D transformations: without it, we can only turn (x,y) coordinates into new coordinates of the form (ax + by, cx + dy), which means we can't do translation, since that requires we end up with some kind of (x + a, y + b). If we add a bogus z coordinate that is always 1, then we can suddenly add arbitrary values. For example:

Sweet! z stays 1, so we can effectively ignore it entirely, but we added some plain values to our x and y coordinates. So, if we want to subtract p1.x and p1.y, we use:

Running all our coordinates through this transformation gives a new set of coordinates, let's call those U, where the first coordinate lies on (0,0), and the rest is still somewhat free. Our next job is to make sure point 2 ends up lying on the x=0 line, so what we want is a transformation matrix that, when we run it, subtracts x from whatever x we currently have. This is called shearing, and the typical x-shear matrix and its transformation looks like this:

So we want some shearing value that, when multiplied by y, yields -x, so our x coordinate becomes zero. That value is simply -x/y, because -x/y \ y = -x*. Done:

Now, running this on all our points generates a new set of coordinates, let's call those V, which now have point 1 on (0,0) and point 2 on (0, some-value), and we wanted it at (0,1), so we need to do some scaling to make sure it ends up at (0,1). Additionally, we want point 3 to end up on (1,1), so we can also scale x to make sure its x-coordinate will be 1 after we run the transform. That means we'll be x-scaling by 1/point3x, and y-scaling by point2y. This is really easy:

Then, finally, this generates a new set of coordinates, let's call those W, of which point 1 lies on (0,0), point 2 lies on (0,1), and
point three lies on (1, ...) so all that's left is to make sure point 3 ends up at (1,1) - but we can't scale! Point 2 is already in the
right place, and y-scaling would move it out of (0,1) again, so our only option is to y-shear point three, just like how we x-sheared
point 2 earlier. In this case, we do the same trick, but with y/x rather than x/y because we're not x-shearing
but y-shearing. Additionally, we don't actually want to end up at zero (which is what we did before) so we need to shear towards an
offset, in this case 1:

And this generates our final set of four coordinates. Of these, we already know that points 1 through 3 are (0,0), (0,1) and (1,1), and only the last coordinate is "free". In fact, given any four starting coordinates, the resulting "transformation mapped" coordinate will be:

Okay, well, that looks plain ridiculous, but: notice that every coordinate value is being offset by the initial translation, and also notice that a lot of terms in that expression are repeated. Even though the maths looks crazy as a single expression, we can just pull this apart a little and end up with an easy-to-calculate bit of code!
First, let's just do that translation step as a "preprocessing" operation so we don't have to subtract the values all the time. What does that leave?

Suddenly things look a lot simpler: the mapped x is fairly straight forward to compute, and we see that the mapped y actually contains the mapped x in its entirety, so we'll have that part already available when we need to evaluate it. In fact, let's pull out all those common factors to see just how simple this is:

That's kind of super-simple to write out in code, I think you'll agree. Coding math tends to be easier than the formulae initially make it look!
How do you track all that?
Doing maths can be a pain, so whenever possible, I like to make computers do the work for me. Especially for things like this, I simply use Mathematica. Tracking all this math by hand is insane, and we invented computers, literally, to do this for us. I have no reason to use pen and paper when I can write out what I want to do in a program, and have the program do the math for me. And real math, too, with symbols, not with numbers. In fact, here's the Mathematica notebook if you want to see how this works for yourself.
Now, I know, you're thinking "but Mathematica is super expensive!" and that's true, it's $344 for home use, up from $295 when I original wrote this, but it's also free when you buy a $35 raspberry pi. Obviously, I bought a raspberry pi, and I encourage you to do the same. With that, as long as you know what you want to do, Mathematica can just do it for you. And we don't have to be geniuses to work out what the maths looks like. That's what we have computers for.
So, let's write up a sketch that'll show us the canonical form for any curve drawn in blue, overlaid on our canonical map, so that we can immediately tell which features our curve must have, based on where the fourth coordinate is located on the map:
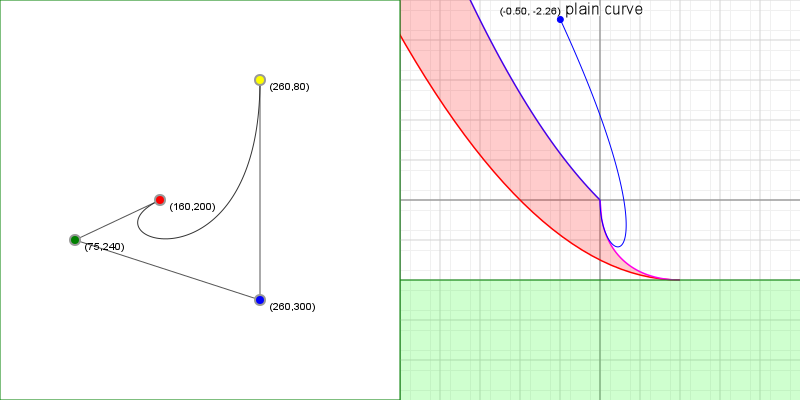
Finding Y, given X
One common task that pops up in things like CSS work, or parametric equalizers, or image leveling, or any other number of applications where Bézier curves are used as control curves in a way that there is really only ever one "y" value associated with one "x" value, you might want to cut out the middle man, as it were, and compute "y" directly based on "x". After all, the function looks simple enough, finding the "y" value should be simple too, right? Unfortunately, not really. However, it is possible and as long as you have some code in place to help, it's not a lot of a work either.
We'll be tackling this problem in two stages: the first, which is the hard part, is figuring out which "t" value belongs to any given "x"
value. For instance, have a look at the following graphic. On the left we have a Bézier curve that looks for all intents and purposes like
it fits our criteria: every "x" has one and only one associated "y" value. On the right we see the function for just the "x" values:
that's a cubic curve, but not a really crazy cubic curve. If you move the graphic's slider, you will see a red line drawn that corresponds
to the x coordinate: this is a vertical line in the left graphic, and a horizontal line on the right.
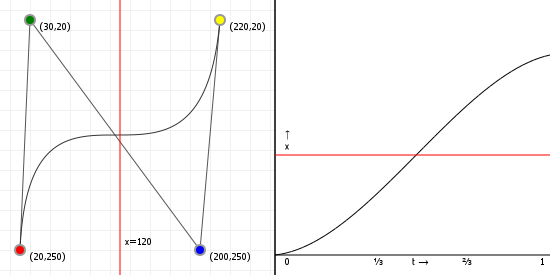
Now, if you look more closely at that right graphic, you'll notice something interesting: if we treat the red line as "the x axis", then the point where the function crosses our line is really just a root for the cubic function x(t) through a shifted "x-axis"... and we've already seen how to calculate roots, so let's just run cubic root finding - and not even the complicated cubic case either: because of the kind of curve we're starting with, we know there is at most a single root in the interval [0,1], simplifying the code we need!
First, let's look at the function for x(t):

We can rewrite this to a plain polynomial form, by just fully writing out the expansion and then collecting the polynomial factors, as:

Nothing special here: that's a standard cubic polynomial in "power" form (i.e. all the terms are ordered by their power of
t). So, given that a, b, c, d, and x(t) are all
known constants, we can trivially rewrite this (by moving the x(t) across the equal sign) as:

You might be wondering "where did all the other 'minus x' for all the other values a, b, c, and d go?" and the answer there is that they all cancel out, so the only one we actually need to subtract is the one at the end. Handy! So now we just solve this equation using Cardano's algorithm, and we're left with some rather short code:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 |
So the procedure is fairly straight forward: pick an x, find the associated t value, evaluate our curve
for that t value, which gives us the curve's {x,y} coordinate, which means we know y for this
x. Move the slider for the following graphic to see this in action:
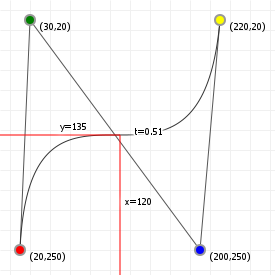
Arc length
How long is a Bézier curve? As it turns out, that's not actually an easy question, because the answer requires maths that —much like root finding— cannot generally be solved the traditional way. If we have a parametric curve with fx(t) and fy(t), then the length of the curve, measured from start point to some point t = z, is computed using the following seemingly straight forward (if a bit overwhelming) formula:

or, more commonly written using Leibnitz notation as:

This formula says that the length of a parametric curve is in fact equal to the area underneath a function that looks a remarkable amount like Pythagoras' rule for computing the diagonal of a straight angled triangle. This sounds pretty simple, right? Sadly, it's far from simple... cutting straight to after the chase is over: for quadratic curves, this formula generates an unwieldy computation, and we're simply not going to implement things that way. For cubic Bézier curves, things get even more fun, because there is no "closed form" solution, meaning that due to the way calculus works, there is no generic formula that allows you to calculate the arc length. Let me just repeat this, because it's fairly crucial: for cubic and higher Bézier curves, there is no way to solve this function if you want to use it "for all possible coordinates".
Seriously: It cannot be done.
So we turn to numerical approaches again. The method we'll look at here is the Gauss quadrature. This approximation is a really neat trick, because for any nth degree polynomial it finds approximated values for an integral really efficiently. Explaining this procedure in length is way beyond the scope of this page, so if you're interested in finding out why it works, I can recommend the University of South Florida video lecture on the procedure, linked in this very paragraph. The general solution we're looking for is the following:

In plain text: an integral function can always be treated as the sum of an (infinite) number of (infinitely thin) rectangular strips sitting "under" the function's plotted graph. To illustrate this idea, the following graph shows the integral for a sinusoid function. The more strips we use (and of course the more we use, the thinner they get) the closer we get to the true area under the curve, and thus the better the approximation:
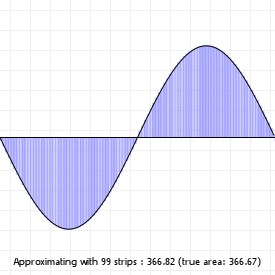
Now, infinitely many terms to sum and infinitely thin rectangles are not something that computers can work with, so instead we're going to approximate the infinite summation by using a sum of a finite number of "just thin" rectangular strips. As long as we use a high enough number of thin enough rectangular strips, this will give us an approximation that is pretty close to what the real value is.
So, the trick is to come up with useful rectangular strips. A naive way is to simply create n strips, all with the same width, but there is a far better way using special values for C and f(t) depending on the value of n, which indicates how many strips we'll use, and it's called the Legendre-Gauss quadrature.
This approach uses strips that are not spaced evenly, but instead spaces them in a special way based on describing the function as a polynomial (the more strips, the more accurate the polynomial), and then computing the exact integral for that polynomial. We're essentially performing arc length computation on a flattened curve, but flattening it based on the intervals dictated by the Legendre-Gauss solution.
Note that one requirement for the approach we'll use is that the integral must run from -1 to 1. That's no good, because we're dealing with Bézier curves, and the length of a section of curve applies to values which run from 0 to "some value smaller than or equal to 1" (let's call that value z). Thankfully, we can quite easily transform any integral interval to any other integral interval, by shifting and scaling the inputs. Doing so, we get the following:

That may look a bit more complicated, but the fraction involving z is a fixed number, so the summation, and the evaluation of the f(t) values are still pretty simple.
So, what do we need to perform this calculation? For one, we'll need an explicit formula for f(t), because that derivative notation is handy on paper, but not when we have to implement it. We'll also need to know what these Ci and ti values should be. Luckily, that's less work because there are actually many tables available that give these values, for any n, so if we want to approximate our integral with only two terms (which is a bit low, really) then these tables would tell us that for n=2 we must use the following values:

Which means that in order for us to approximate the integral, we must plug these values into the approximate function, which gives us:

We can program that pretty easily, provided we have that f(t) available, which we do, as we know the full description for the Bézier curve functions Bx(t) and By(t).
If we use the Legendre-Gauss values for our C values (thickness for each strip) and t values (location of each strip), we can determine the approximate length of a Bézier curve by computing the Legendre-Gauss sum. The following graphic shows a cubic curve, with its computed lengths; Go ahead and change the curve, to see how its length changes. One thing worth trying is to see if you can make a straight line, and see if the length matches what you'd expect. What if you form a line with the control points on the outside, and the start/end points on the inside?
Approximated arc length
Sometimes, we don't actually need the precision of a true arc length, and we can get away with simply computing the approximate arc length instead. The by far fastest way to do this is to flatten the curve and then simply calculate the linear distance from point to point. This will come with an error, but this can be made arbitrarily small by increasing the segment count.
If we combine the work done in the previous sections on curve flattening and arc length computation, we can implement these with minimal effort:

You may notice that even though the error in length is actually pretty significant in absolute terms, even at a low number of segments we get a length that agrees with the true length when it comes to just the integer part of the arc length. Quite often, approximations can drastically speed things up!
Curvature of a curve
If we have two curves, and we want to line them in up in a way that "looks right", what would we use as metric to let a computer decide what "looks right" means?
For instance, we can start by ensuring that the two curves share an end coordinate, so that there is no "gap" between the end of one and the start of the next curve, but that won't guarantee that things look right: both curves can be going in wildly different directions, and the resulting joined geometry will have a corner in it, rather than a smooth transition from one curve to the next.
What we want is to ensure that the curvature at the transition from one curve to the next "looks good". So, we start with a shared coordinate, and then also require that derivatives for both curves match at that coordinate. That way, we're assured that their tangents line up, which must mean the curve transition is perfectly smooth. We can even make the second, third, etc. derivatives match up for better and better transitions.
Problem solved!
However, there's a problem with this approach: if we think about this a little more, we realise that "what a curve looks like" and its derivative values are pretty much entirely unrelated. After all, the section on reordering curves showed us that the same looking curve can have an infinite number of curve expressions of arbitrarily high Bézier degree, and each of those will have wildly different derivative values.
So what we really want is some kind of expression that's not based on any particular expression of t, but is based on
something that is invariant to the kind of function(s) we use to draw our curve. And the prime candidate for this is our curve
expression, reparameterised for distance: no matter what order of Bézier curve we use, if we were able to rewrite it as a function of
distance-along-the-curve, all those different degree Bézier functions would end up being the same function for "coordinate at
some distance D along the curve".
We've seen this before... that's the arc length function.
So you might think that in order to find the curvature of a curve, we now need to solve the arc length function itself, and that this would be quite a problem because we just saw that there is no way to actually do that. Thankfully, we don't. We only need to know the form of the arc length function, which we saw above and is fairly simple, rather than needing to solve the arc length function. If we start with the arc length expression and the run through the steps necessary to determine its derivative (with an alternative, shorter demonstration of how to do this found over on Stackexchange), then the integral that was giving us so much problems in solving the arc length function disappears entirely (because of the fundamental theorem of calculus), and what we're left with us some surprisingly simple maths that relates curvature (denoted as κ, "kappa") to—and this is the truly surprising bit—a specific combination of derivatives of our original function.
Let me highlight what just happened, because it's pretty special:
- we wanted to make curves line up, and initially thought to match the curves' derivatives, but
- that turned out to be a really bad choice, so instead
- we picked a function that is basically impossible to work with, and then worked with that, which
- gives us a simple formula that is and expression using the curves' derivatives.
That's crazy!
But that's also one of the things that makes maths so powerful: even if your initial ideas are off the mark, you might be much closer than you thought you were, and the journey from "thinking we're completely wrong" to "actually being remarkably close to being right" is where we can find a lot of insight.
So, what does the function look like? This:

Which is really just a "short form" that glosses over the fact that we're dealing with functions of t, so let's expand that a
tiny bit:

And while that's a little more verbose, it's still just as simple to work with as the first function: the curvature at some point on any (and this cannot be overstated: any) curve is a ratio between the first and second derivative cross product, and something that looks oddly similar to the standard Euclidean distance function. And nothing in these functions is hard to calculate either: for Bézier curves, simply knowing our curve coordinates means we know what the first and second derivatives are, and so evaluating this function for any t value is just a matter of basic arithematics.
In fact, let's just implement it right now:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 |
That was easy! (Well okay, that "not a number" value will need to be taken into account by downstream code, but that's a reality of programming anyway)
With all of that covered, let's line up some curves! The following graphic gives you two curves that look identical, but use quadratic and cubic functions, respectively. As you can see, despite their derivatives being necessarily different, their curvature (thanks to being derived based on maths that "ignores" specific function derivative, and instead gives a formula that smooths out any differences) is exactly the same. And because of that, we can put them together such that the point where they overlap has the same curvature for both curves, giving us the smoothest transition.
One thing you may have noticed in this sketch is that sometimes the curvature looks fine, but seems to be pointing in the wrong direction, making it hard to line up the curves properly. A way around that, of course, is to show the curvature on both sides of the curve, so let's just do that. But let's take it one step further: we can also compute the associated "radius of curvature", which gives us the implicit circle that "fits" the curve's curvature at any point, using what is possibly the simplest bit of maths found in this entire primer:

So let's revisit the previous graphic with the curvature visualised on both sides of our curves, as well as showing the circle that "fits" our curve at some point that we can control by using a slider:
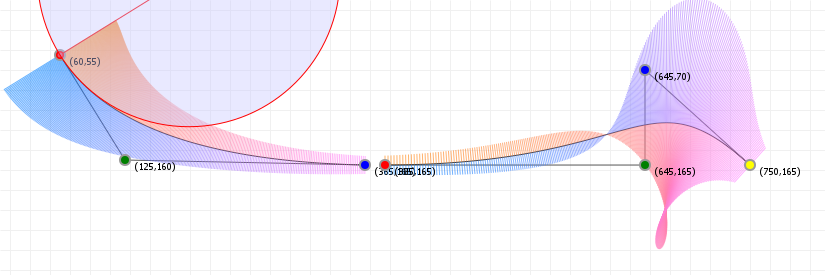
Tracing a curve at fixed distance intervals
Say you want to draw a curve with a dashed line, rather than a solid line, or you want to move something along the curve at fixed distance intervals over time, like a train along a track, and you want to use Bézier curves.
Now you have a problem.
The reason you have a problem is that Bézier curves are parametric functions with non-linear behaviour, whereas moving a train along a
track is about as close to a practical example of linear behaviour as you can get. The problem we're faced with is that we can't just pick
t values at some fixed interval and expect the Bézier functions to generate points that are spaced a fixed distance apart. In
fact, let's look at the relation between "distance along a curve" and "t value", by plotting them against one another.
The following graphic shows a particularly illustrative curve, and its distance-for-t plot. For linear traversal, this line needs to be straight, running from (0,0) to (length,1). That is, it's safe to say, not what we'll see: we'll see something very wobbly, instead. To make matters even worse, the distance-for-t function is also of a much higher order than our curve is: while the curve we're using for this exercise is a cubic curve, which can switch concave/convex form twice at best, the distance function is our old friend the arc length function, which can have more inflection points.
So, how do we "cut up" the arc length function at regular intervals, when we can't really work with it? We basically cheat: we run through
the curve using t values, determine the distance-for-this-t-value at each point we generate during the run, and
then we find "the closest t value that matches some required distance" using those values instead. If we have a low number of
points sampled, we can then even refine which t value "should" work for our desired distance by interpolating between two
points, but if we have a high enough number of samples, we don't even need to bother.
So let's do exactly that: the following graph is similar to the previous one, showing how we would have to "chop up" our distance-for-t
curve in order to get regularly spaced points on the curve. It also shows what using those t values on the real curve looks
like, by coloring each section of curve between two distance markers differently:
Use the slider to increase or decrease the number of equidistant segments used to colour the curve.
However, are there better ways? One such way is discussed in "Moving Along a Curve with Specified Speed" by David Eberly of Geometric Tools, LLC, but basically because we have no explicit length function (or rather, one we don't have to constantly compute for different intervals), you may simply be better off with a traditional lookup table (LUT).
Intersections
Let's look at some more things we will want to do with Bézier curves. Almost immediately after figuring out how to get bounding boxes to work, people tend to run into the problem that even though the minimal bounding box (based on rotation) is tight, it's not sufficient to perform true collision detection. It's a good first step to make sure there might be a collision (if there is no bounding box overlap, there can't be one), but in order to do real collision detection we need to know whether or not there's an intersection on the actual curve.
We'll do this in steps, because it's a bit of a journey to get to curve/curve intersection checking. First, let's start simple, by implementing a line-line intersection checker. While we can solve this the traditional calculus way (determine the functions for both lines, then compute the intersection by equating them and solving for two unknowns), linear algebra actually offers a nicer solution.
Line-line intersections
If we have two line segments with two coordinates each, segments A-B and C-D, we can find the intersection of the lines these segments are an intervals on by linear algebra, using the procedure outlined in this top coder article. Of course, we need to make sure that the intersection isn't just on the lines our line segments lie on, but actually on our line segments themselves. So after we find the intersection, we need to verify that it lies without the bounds of our original line segments.
The following graphic implements this intersection detection, showing a red point for an intersection on the lines our segments lie on (thus being a virtual intersection point), and a green point for an intersection that lies on both segments (being a real intersection point).
Implementing line-line intersections
Let's have a look at how to implement a line-line intersection checking function. The basics are covered in the article mentioned above, but sometimes you need more function signatures, because you might not want to call your function with eight distinct parameters. Maybe you're using point structs for the line. Let's get coding:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 | |
| 14 | |
| 15 | |
| 16 | |
| 17 |
What about curve-line intersections?
Curve/line intersection is more work, but we've already seen the techniques we need to use in order to perform it: first we translate/rotate both the line and curve together, in such a way that the line coincides with the x-axis. This will position the curve in a way that makes it cross the line at points where its y-function is zero. By doing this, the problem of finding intersections between a curve and a line has now become the problem of performing root finding on our translated/rotated curve, as we already covered in the section on finding extremities.

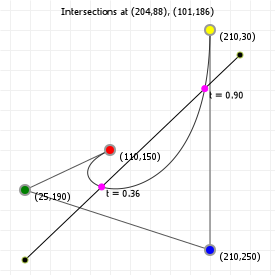
Curve/curve intersection, however, is more complicated. Since we have no straight line to align to, we can't simply align one of the curves and be left with a simple procedure. Instead, we'll need to apply two techniques we've met before: de Casteljau's algorithm, and curve splitting.
Curve/curve intersection
Using de Casteljau's algorithm to split the curve we can now implement curve/curve intersection finding using a "divide and conquer" technique:
- Take two curves C1 and C2, and treat them as a pair.
- If their bounding boxes overlap, split up each curve into two sub-curves
- With C1.1, C1.2, C2.1 and C2.2, form four new pairs (C1.1,C2.1), (C1.1, C2.2), (C1.2,C2.1), and (C1.2,C2.2).
-
For each pair, check whether their bounding boxes overlap.
- If their bounding boxes do not overlap, discard the pair, as there is no intersection between this pair of curves.
- If there is overlap, rerun all steps for this pair.
-
Once the sub-curves we form are so small that they effectively occupy sub-pixel areas, we consider an intersection found, noting that we
might have a cluster of multiple intersections at the sub-pixel level, out of which we pick one to act as "found"
tvalue (we can either throw all but one away, we can average the cluster'stvalues, or you can do something even more creative).
This algorithm will start with a single pair, "balloon" until it runs in parallel for a large number of potential sub-pairs, and then taper back down as it homes in on intersection coordinates, ending up with as many pairs as there are intersections.
The following graphic applies this algorithm to a pair of cubic curves, one step at a time, so you can see the algorithm in action. Click the button to run a single step in the algorithm, after setting up your curves in some creative arrangement. You can also change the value that is used in step 5 to determine whether the curves are small enough. Manipulating the curves or changing the threshold will reset the algorithm, so you can try this with lots of different curves.
(can you find the configuration that yields the maximum number of intersections between two cubic curves? Nine intersections!)
Finding self-intersections is effectively the same procedure, except that we're starting with a single curve, so we need to turn that into
two separate curves first. This is trivially achieved by splitting at an inflection point, or if there are none, just splitting at
t=0.5 first, and then running the exact same algorithm as above, with all non-overlapping curve pairs getting removed at each
iteration, and each successive step homing in on the curve's self-intersection points.
The projection identity
De Casteljau's algorithm is the pivotal algorithm when it comes to Bézier curves. You can use it not just to split curves, but also to draw them efficiently (especially for high-order Bézier curves), as well as to come up with curves based on three points and a tangent. Particularly this last thing is really useful because it lets us "mold" a curve, by picking it up at some point, and dragging that point around to change the curve's shape.
How does that work? Succinctly: we run de Casteljau's algorithm in reverse!
In order to run de Casteljau's algorithm in reverse, we need a few basic things: a start and end point, a point on the curve that we want to be moving around, which has an associated t value, and a point we've not explicitly talked about before, and as far as I know has no explicit name, but lives one iteration higher in the de Casteljau process then our on-curve point does. I like to call it "A" for reasons that will become obvious.
So let's use graphics instead of text to see where this "A" is, because text only gets us so far: move the sliders for the following
graphics to see what, given a specific t value, our A coordinate is. As well as some other coordinates, which
taken together let us derive a value that the graphics call "ratio": if you move the curve's points around, A, B, and C will move, what
happens to that value?
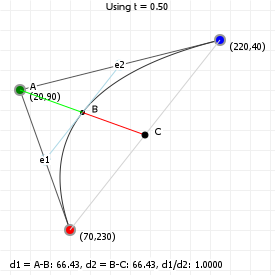
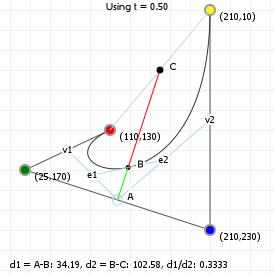
So these graphics show us several things:
- a point at the tip of the curve construction's "hat": let's call that
A, as well as - our on-curve point give our chosen
tvalue: let's call thatB, and finally, -
a point that we get by projecting A, through B, onto the line between the curve's start and end points: let's call that
C. -
for both quadratic and cubic curves, two points
e1ande2, which represent the single-to-last step in de Casteljau's algorithm: in the last step, we findBat(1-t) * e1 + t * e2. -
for cubic curves, also the points
v1andv2, which together withArepresent the first step in de Casteljau's algorithm: in the next step, we finde1ande2.
These three values A, B, and C allow us to derive an important identity formula for quadratic and cubic Bézier curves: for any point on
the curve with some t value, the ratio of distances from A to B and B to C is fixed: if some t value sets up a C
that is 20% away from the start and 80% away from the end, then it doesn't matter where the start, end, or control points are;
for that t value, C will always lie at 20% from the start and 80% from the end point. Go ahead, pick an
on-curve point in either graphic and then move all the other points around: if you only move the control points, start and end won't move,
and so neither will C, and if you move either start or end point, C will move but its relative position will not change.
So, how can we compute C? We start with our observation that C always lies somewhere between the start and end
points, so logically C will have a function that interpolates between those two coordinates:

If we can figure out what the function u(t) looks like, we'll be done. Although we do need to remember that this
u(t) will have a different form depending on whether we're working with quadratic or cubic curves.
Running through the maths
(with thanks to Boris Zbarsky) shows us the following two formulae:

And

So, if we know the start and end coordinates and the t value, we know C without having to calculate the A or even
B coordinates. In fact, we can do the same for the ratio function. As another function of t, we technically
don't need to know what A or B or C are. It, too, can be expressed as a pure function of
t.
We start by observing that, given A, B, and C, the following always holds:

Working out the maths for this, we see the following two formulae for quadratic and cubic curves:

And

Which now leaves us with some powerful tools: given three points (start, end, and "some point on the curve"), as well as a
t value, we can construct curves. We can compute C using the start and end points and our
u(t) function, and once we have C, we can use our on-curve point (B) and the
ratio(t) function to find A:

With A found, finding e1 and e2 for quadratic curves is a matter of running the linear
interpolation with t between start and A to yield e1, and between A and end to yield
e2. For cubic curves, there is no single pair of points that can act as e1 and e2 (there are
infinitely many, because the tangent at B is a free parameter for cubic curves) so as long as the distance ratio between
e1 to B and B to e2 is the Bézier ratio (1-t):t, we are free to pick any
pair, after which we can reverse engineer v1 and v2:

And then reverse engineer the curve's control points:

So: if we have a curve's start and end points, as well as some third point B that we want the curve to pass through, then for any
t value we implicitly know all the ABC values, which (combined with an educated guess on appropriate e1 and
e2 coordinates for cubic curves) gives us the necessary information to reconstruct a curve's "de Casteljau skeleton". Which
means that we can now do several things: we can "fit" curves using only three points, which means we can also "mold" curves by moving an
on-curve point but leaving its start and end points, and then reconstruct the curve based on where we moved the on-curve point to. These
are very useful things, and we'll look at both in the next few sections.
Creating a curve from three points
Given the preceding section, you might be wondering if we can use that knowledge to just "create" curves by placing some points and having the computer do the rest, to which the answer is: that's exactly what we can now do!
For quadratic curves, things are pretty easy. Technically, we'll need a t value in order to compute the ratio function used
in computing the ABC coordinates, but we can just as easily approximate one by treating the distance between the start and
B point, and B and end point as a ratio, using

With this code in place, creating a quadratic curve from three points is literally just computing the ABC values, and using
A as our curve's control point:
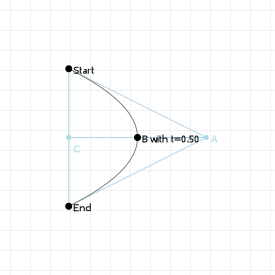
For cubic curves we need to do a little more work, but really only just a little. We're first going to assume that a decent curve through the three points should approximate a circular arc, which first requires knowing how to fit a circle to three points. You may remember (if you ever learned it!) that a line between two points on a circle is called a chord, and that one property of chords is that the line from the center of any chord, perpendicular to that chord, passes through the center of the circle.
That means that if we have three points on a circle, we have three (different) chords, and consequently, three (different) lines that go from those chords through the center of the circle: if we find two of those lines, then their intersection will be our circle's center, and the circle's radius will—by definition!—be the distance from the center to any of our three points:
With that covered, we now also know the tangent line to our point B, because the tangent to any point on the circle is a line
through that point, perpendicular to the line from that point to the center. That just leaves marking appropriate points
e1 and e2 on that tangent, so that we can construct a new cubic curve hull. We use the approach as we did for
quadratic curves to automatically determine a reasonable t value, and then our e1 and
e2 coordinates must obey the standard de Casteljau rule for linear interpolation:

Where d is the total length of the line segment from e1 to e2. So how long do we make that? There
are again all kinds of approaches we can take, and a simple-but-effective one is to set the length of that segment to "one third the
length of the baseline". This forces e1 and e2 to always be the "linear curve" distance apart, which means if we
place our three points on a line, it will actually look like a line. Nice! The last thing we'll need to do is make sure to flip
the sign of d depending on which side of the baseline our B is located, so we don't end up creating a funky
curve with a loop in it. To do this, we can use the atan2 function:

This angle φ will be between 0 and π if B is "above" the baseline (rotating all three points so that the start is on the left
and the end is the right), so we can use a relatively straight forward check to make sure we're using the correct sign for our value
d:

The result of this approach looks as follows:
It is important to remember that even though we're using a circular arc to come up with decent e1 and e2 terms,
we're not trying to perfectly create a circular arc with a cubic curve (which is good, because we can't;
more on that later), we're only trying to come up with some reasonable e1 and
e2 points so we can construct a new cubic curve... so now that we have those: let's see what kind of cubic curve that gives
us:
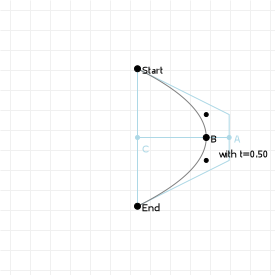
That looks perfectly serviceable!
Of course, we can take this one step further: we can't just "create" curves, we also have (almost!) all the tools available to "mold" curves, where we can reshape a curve by dragging a point on the curve around while leaving the start and end fixed, effectively molding the shape as if it were clay or the like. We'll see the last tool we need to do that in the next section, and then we'll look at implementing curve molding in the section after that, so read on!
Projecting a point onto a Bézier curve
Before we can move on to actual curve molding, it'll be good if know how to actually be able to find "some point on the curve" that we're trying to click on. After all, if all we have is our Bézier coordinates, that is not in itself enough to figure out which point on the curve our cursor will be closest to. So, how do we project points onto a curve?
If the Bézier curve is of low enough order, we might be able to
work out the maths for how to do this, and get a perfect t value back, but in general this is an incredibly hard problem and the easiest solution is, really, a
numerical approach again. We'll be finding our ideal t value using a
binary search. First, we do a coarse distance-check based on
t values associated with the curve's "to draw" coordinates (using a lookup table, or LUT). This is pretty fast:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 |
After this runs, we know that LUT[i] is the coordinate on the curve in our LUT that is closest to the point we want
to project, so that's a pretty good initial guess as to what the best projection onto our curve is. To refine it, we note that
LUT[i] is a better guess than both LUT[i-1] and LUT[i+1], but there might be an even better
projection somewhere else between those two values, so that's what we're going to be testing for, using a variation of the binary
search.
-
we start with our point
p, and thetvaluest1=LUT[i-1].tandt2=LUT[i+1].t, which span an intervalv = t2-t1. - we test this interval in five spots: the start, middle, and end (which we already have), and the two points in between the middle and start/end points
-
we then check which of these five points is the closest to our original point
p, and then repeat step 1 with the points before and after the closest point we just found.
This makes the interval we check smaller and smaller at each iteration, and we can keep running the three steps until the interval becomes so small as to lead to distances that are, for all intents and purposes, the same for all points.
So, let's see that in action: in this case, I'm going to arbitrarily say that if we're going to run the loop until the interval is smaller than 0.001, and show you what that means for projecting your mouse cursor or finger tip onto a rather complex Bézier curve (which, of course, you can reshape as you like). Also shown are the original three points that our coarse check finds.
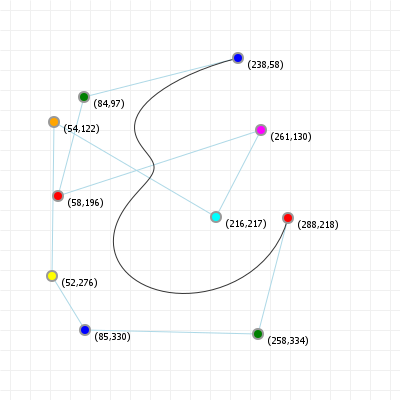
Intersections with a circle
It might seem odd to cover this subject so much later than the line/line, line/curve, and curve/curve intersection topics from several sections earlier, but the reason we can't cover circle/curve intersections is that we can't really discuss circle/curve intersection until we've covered the kind of lookup table (LUT) walking that the section on projecting a point onto a curve uses. To see why, let's look at what we would have to do if we wanted to find the intersections between a curve and a circle using calculus.
First, we observe that "finding intersections" in this case means that, given a circle defined by a center point
c = (x,y) and a radius r, we want to find all points on the Bezier curve for which the distance to the circle's
center point is equal to the circle radius, which by definition means those points lie on the circle, and so count as intersections. In
maths, that means we're trying to solve:

Which seems simple enough. Unfortunately, when we expand that dist function, things get a lot more problematic:

And now we have a problem because that's a sixth degree polynomial inside the square root. So, thanks to the Abel-Ruffini theorem that we saw before, we can't solve this by just going "square both sides because we don't care about signs"... we can't solve a sixth degree polynomial. So, we're going to have to actually evaluate that expression. We can "simplify" this by translating all our coordinates so that the center of the circle is (0,0) and all our coordinates are shifted accordingly, which makes the cx and cy terms fall away, but then we're still left with a monstrous function to solve.
So instead, we turn to the same kind of "LUT walking" that we saw for projecting points onto a curve, with a twist: instead of finding the
on-curve point with the smallest distance to our projection point, we want to find the on-curve point that has the exact distance
r to our projection point (namely, our circle center). Of course, there can be more than one such point, so there's also a
bit more code to make sure we find all of them, but let's look at the steps involved:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 |
This is very similar to the code in the previous section, with an extra input r for the circle radius, and a minor
change in the "distance for this coordinate": rather than just distance(coordinate, p) we want to know the difference between
that distance and the circle radius. After all, if that difference is zero, then the distance from the coordinate to the circle center is
exactly the radius, so the coordinate lies on both the curve and the circle.
So far so good.
However, we also want to make sure we find all the points, not just a single one, so we need a little more code for that:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 |
After running this code, values will be the list of all LUT coordinates that are closest to the distance r: we
can use those values to run the same kind of refinement lookup we used for point projection (with the caveat that we're now
not checking for smallest distance, but for "distance closest to r"), and we'll have all our intersection points. Of
course, that does require explaining what findClosest does: rather than looking for a global minimum, we're now interested in
finding a local minimum, so instead of checking a single point and looking at its distance value, we check three points
("current", "previous" and "before previous") and then check whether they form a local minimum:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 | |
| 14 | |
| 15 | |
| 16 | |
| 17 | |
| 18 | |
| 19 |
In words: given a start index, the circle center and radius, and our LUT, we check where (closest to our
start index) we can find a local minimum for the difference between "the distance from the curve to the circle center", and
the circle's radius. We track this by looking at three values (associated with the indices index-2, index-1, and
index), and we know we've found a local minimum if the three values show that the middle value (pd1) is less
than either value beside it. When we do, we can set our "best guess, relative to start" as index-1. Of course,
since we're now checking values relative to some start value, we might not find another candidate value at all, in which case
we return start - 1, so that a simple "is the result less than start?" lets us determine that there are no more
intersections to find.
Finally, while not necessary for point projection, there is one more step we need to perform when we run the binary refinement function on
our candidate LUT indices, because we've so far only been testing using distances "closest to the radius of the circle", and that's
actually not good enough... we need distances that are the radius of the circle. So, after running the refinement for each of
these indices, we need to discard any final value that isn't the circle radius. And because we're working with floating point numbers,
what this really means is that we need to discard any value that's a pixel or more "off". Or, if we want to get really fancy, "some small
epsilon value".
Based on all of that, the following graphic shows this off for the standard cubic curve (which you can move the coordinates around for, of course) and a circle with a controllable radius centered on the graphic's center, using the code approach described above.
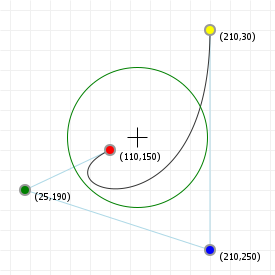
And of course, for the full details, click that "view source" link.
Molding a curve
Armed with knowledge of the "ABC" relation, point-on-curve projection, and guestimating reasonable looking helper values for cubic curve construction, we can finally cover curve molding: updating a curve's shape interactively, by dragging points on the curve around.
For quadratic curve, this is a really simple trick: we project our cursor onto the curve, which gives us a t value and
initial B coordinate. We don't even need the latter: with our t value and "wherever the cursor is" as target
B, we can compute the associated C:

And then the associated A:

And we're done, because that's our new quadratic control point!
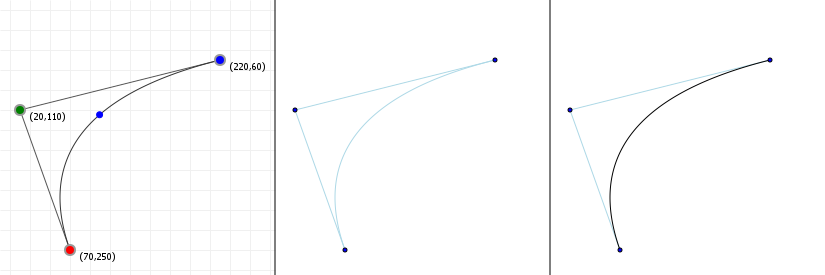
As before, cubic curves are a bit more work, because while it's easy to find our initial t value and ABC values, getting
those all-important e1 and e2 coordinates is going to pose a bit of a problem... in the section on curve
creation, we were free to pick an appropriate t value ourselves, which allowed us to find appropriate e1 and
e2 coordinates. That's great, but when we're curve molding we don't have that luxury: whatever point we decide to start
moving around already has its own t value, and its own e1 and e2 values, and those may not make
sense for the rest of the curve.
For example, let's see what happens if we just "go with what we get" when we pick a point and start moving it around, preserving its
t value and e1/e2 coordinates:
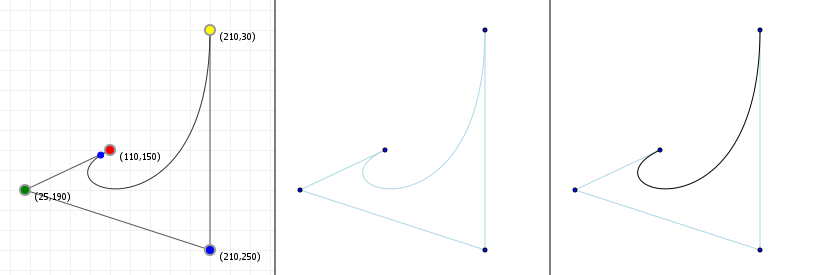
That looks reasonable, close to the original point, but the further we drag our point, the less "useful" things become. Especially if we drag our point across the baseline, rather than turning into a nice curve.
One way to combat this might be to combine the above approach with the approach from the
creating curves section: generate both the "unchanged t/e1/e2" curve, as
well as the "idealized" curve through the start/cursor/end points, with idealized t value, and then interpolating between
those two curves:
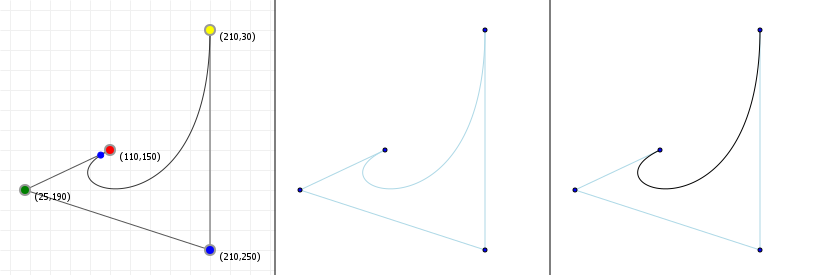
The slide controls the "falloff distance" relative to where the original point on the curve is, so that as we drag our point around, it
interpolates with a bias towards "preserving t/e1/e2" closer to the original point, and bias
towards "idealized" form the further away we move our point, with anything that's further than our falloff distance simply
being the idealized curve. We don't even try to interpolate at that point.
A more advanced way to try to smooth things out is to implement continuous molding, where we constantly update the curve as we
move around, and constantly change what our B point is, based on constantly projecting the cursor on the curve
as we're updating it - this is, you won't be surprised to learn, tricky, and beyond the scope of this section: interpolation
(with a reasonable distance) will do for now!
Curve fitting
Given the previous section, one question you might have is "what if I don't want to guess t values?". After all, plenty of
graphics packages do automated curve fitting, so how can we implement that in a way that just finds us reasonable t values
all on its own?
And really this is just a variation on the question "how do I get the curve through these X points?", so let's look at that. Specifically,
let's look at the answer: "curve fitting". This is in fact a rather rich field in geometry, applying to anything from data modelling to
path abstraction to "drawing", so there's a fair number of ways to do curve fitting, but we'll look at one of the most common approaches:
something called a least squares
polynomial regression. In this approach, we look at the number of points
we have in our data set, roughly determine what would be an appropriate order for a curve that would fit these points, and then tackle the
question "given that we want an nth order curve, what are the coordinates we can find such that our curve is "off" by the
least amount?".
Now, there are many ways to determine how "off" points are from the curve, which is where that "least squares" term comes in. The most common tool in the toolbox is to minimise the squared distance between each point we have, and the corresponding point on the curve we end up "inventing". A curve with a snug fit will have zero distance between those two, and a bad fit will have non-zero distances between every such pair. It's a workable metric. You might wonder why we'd need to square, rather than just ensure that distance is a positive value (so that the total error is easy to compute by just summing distances) and the answer really is "because it tends to be a little better". There's lots of literature on the web if you want to deep-dive the specific merits of least squared error metrics versus least absolute error metrics, but those are well beyond the scope of this material.
So let's look at what we end up with in terms of curve fitting if we start with the idea of performing least squares Bézier fitting. We're going to follow a procedure similar to the one described by Jim Herold over on his "Least Squares Bézier Fit" article, and end with some nice interactive graphics for doing some curve fitting.
Before we begin, we're going to use the curve in matrix form. In the section on matrices, I mentioned that some things are easier if we use the matrix representation of a Bézier curve rather than its calculus form, and this is one of those things.
As such, the first step in the process is expressing our Bézier curve as powers/coefficients/coordinate matrix T x M x C, by expanding the Bézier functions.
Revisiting the matrix representation
Rewriting Bézier functions to matrix form is fairly easy, if you first expand the function, and then arrange them into a multiple line form, where each line corresponds to a power of t, and each column is for a specific coefficient. First, we expand the function:

And then we (trivially) rearrange the terms across multiple lines:

This rearrangement has "factors of t" at each row (the first row is t⁰, i.e. "1", the second row is t¹, i.e. "t", the third row is t²) and "coefficient" at each column (the first column is all terms involving "a", the second all terms involving "b", the third all terms involving "c").
With that arrangement, we can easily decompose this as a matrix multiplication:

We can do the same for the cubic curve, of course. We know the base function for cubics:

So we write out the expansion and rearrange:

Which we can then decompose:

And, of course, we can do this for quartic curves too (skipping the expansion step):

And so and on so on. Now, let's see how to use these T, M, and C, to do some curve fitting.
Let's get started: we're going to assume we picked the right order curve: for n points we're fitting an n-1th order curve, so we "start" with a vector P that represents the coordinates we already know, and for which
we want to do curve fitting:

Next, we need to figure out appropriate t values for each point in the curve, because we need something that lets us tie "the
actual coordinate" to "some point on the curve". There's a fair number of different ways to do this (and a large part of optimizing "the
perfect fit" is about picking appropriate t values), but in this case let's look at two "obvious" choices:
- equally spaced
tvalues, and tvalues that align with distance along the polygon.
The first one is really simple: if we have n points, then we'll just assign each point i a t value
of (i-1)/(n-1). So if we have four points, the first point will have t=(1-1)/(4-1)=0/3, the second point will
have t=(2-1)/(4-1)=1/3, the third point will have t=2/3, and the last point will be t=1. We're just
straight up spacing the t values to match the number of points we have.
The second one is a little more interesting: since we're doing polynomial regression, we might as well exploit the fact that our base
coordinates just constitute a collection of line segments. At the first point, we're fixing t=0, and the last point, we want t=1, and
anywhere in between we're simply going to say that t is equal to the distance along the polygon, scaled to the [0,1] domain.
To get these values, we first compute the general "distance along the polygon" matrix:

Where length() is literally just that: the length of the line segment between the point we're looking at, and the previous
point. This isn't quite enough, of course: we still need to make sure that all the values between i=1 and
i=n fall in the [0,1] interval, so we need to scale all values down by whatever the total length of the polygon is:

And now we can move on to the actual "curve fitting" part: what we want is a function that lets us compute "ideal" control point values such that if we build a Bézier curve with them, that curve passes through all our original points. Or, failing that, have an overall error distance that is as close to zero as we can get it. So, let's write out what the error distance looks like.
As mentioned before, this function is really just "the distance between the actual coordinate, and the coordinate that the curve evaluates
to for the associated t value", which we'll square to get rid of any pesky negative signs:

Since this function only deals with individual coordinates, we'll need to sum over all coordinates in order to get the full error function. So, we literally just do that; the total error function is simply the sum of all these individual errors:

And here's the trick that justifies using matrices: while we can work with individual values using calculus, with matrices we can compute as many values as we make our matrices big, all at the "same time", We can replace the individual terms pi with the full P coordinate matrix, and we can replace Bézier(si) with the matrix representation T x M x C we talked about before, which gives us:

In which we can replace the rather cumbersome "squaring" operation with a more conventional matrix equivalent:

Here, the letter T is used instead of the number 2, to represent the
matrix transpose; each row in the original matrix becomes a column in the transposed
matrix instead (row one becomes column one, row two becomes column two, and so on).
This leaves one problem: T isn't actually the matrix we want: we don't want symbolic t values, we want the
actual numerical values that we computed for S, so we need to form a new matrix, which we'll call 𝕋, that makes use of
those, and then use that 𝕋 instead of T in our error function:

Which, because of the first and last values in S, means:

Now we can properly write out the error function as matrix operations:

So, we have our error function: we now need to figure out the expression for where that function has minimal value, e.g. where the error between the true coordinates and the coordinates generated by the curve fitting is smallest. Like in standard calculus, this requires taking the derivative, and determining where that derivative is zero:

Where did this derivative come from?
That... is a good question. In fact, when trying to run through this approach, I ran into the same question! And you know what? I straight up had no idea. I'm decent enough at calculus, I'm decent enough at linear algebra, and I just don't know.
So I did what I always do when I don't understand something: I asked someone to help me understand how things work. In this specific case, I posted a question to Math.stackexchange, and received a answer that goes into way more detail than I had hoped to receive.
Is that answer useful to you? Probably: no. At least, not unless you like understanding maths on a recreational level. And I do mean maths in general, not just basic algebra. But it does help in giving us a reference in case you ever wonder "Hang on. Why was that true?". There are answers. They might just require some time to come to understand.
Now, given the above derivative, we can rearrange the terms (following the rules of matrix algebra) so that we end up with an expression for C:

Here, the "to the power negative one" is the notation for the
matrix inverse. But that's all we have to do: we're done. Starting with
P and inventing some t values based on the polygon the coordinates in P define, we can
compute the corresponding Bézier coordinates C that specify a curve that goes through our points. Or, if it can't go
through them exactly, as near as possible.
So before we try that out, how much code is involved in implementing this? Honestly, that answer depends on how much you're going to be writing yourself. If you already have a matrix maths library available, then really not that much code at all. On the other hand, if you are writing this from scratch, you're going to have to write some utility functions for doing your matrix work for you, so it's really anywhere from 50 lines of code to maybe 200 lines of code. Not a bad price to pay for being able to fit curves to pre-specified coordinates.
So let's try it out! The following graphic lets you place points, and will start computing exact-fit curves once you've placed at least three. You can click for more points, and the code will simply try to compute an exact fit using a Bézier curve of the appropriate order. Four points? Cubic Bézier. Five points? Quartic. And so on. Of course, this does break down at some point: depending on where you place your points, it might become mighty hard for the fitter to find an exact fit, and things might actually start looking horribly off once there's enough points for compound floating point rounding errors to start making a difference (which is around 10~11 points).
You'll note there is a convenient "toggle" buttons that lets you toggle between equidistant t values, and distance ratio
along the polygon formed by the points. Arguably more interesting is that once you have points to abstract a curve, you also get
direct control over the time values through sliders for each, because if the time values are our degree of freedom, you should be
able to freely manipulate them and see what the effect on your curve is.
Bézier curves and Catmull-Rom curves
Taking an excursion to different splines, the other common design curve is the Catmull-Rom spline, which unlike Bézier curves pass through each control point, so they offer a kind of "built-in" curve fitting.
In fact, let's start with just playing with one: the following graphic has a predefined curve that you manipulate the points for, and lets you add points by clicking/tapping the background, as well as let you control "how fast" the curve passes through its point using the tension slider. The tenser the curve, the more the curve tends towards straight lines from one point to the next.
Now, it may look like Catmull-Rom curves are very different from Bézier curves, because these curves can get very long indeed, but what looks like a single Catmull-Rom curve is actually a spline: a single curve built up of lots of identically-computed pieces, similar to if you just took a whole bunch of Bézier curves, placed them end to end, and lined up their control points so that things look like a single curve. For a Catmull-Rom curve, each "piece" between two points is defined by the point's coordinates, and the tangent for those points, the latter of which can trivially be derived from knowing the previous and next point:

One downside of this is that—as you may have noticed from the graphic—the first and last point of the overall curve don't actually join up with the rest of the curve: they don't have a previous/next point respectively, and so there is no way to calculate what their tangent should be. Which also makes it rather tricky to fit a Catmull-Rom curve to three points like we were able to do for Bézier curves. More on that in the next section.
In fact, before we move on, let's look at how to actually draw the basic form of these curves (I say basic, because there are a number of variations that make things considerable more complex):
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 | |
| 14 | |
| 15 | |
| 16 | |
| 17 | |
| 18 | |
| 19 |
Now, since a Catmull-Rom curve is a form of cubic Hermite spline, and as cubic Bézier curves are also a form of cubic Hermite spline, we run into an interesting bit of maths programming: we can convert one to the other and back, and the maths for doing so is surprisingly simple!
The main difference between Catmull-Rom curves and Bézier curves is "what the points mean":
- A cubic Bézier curve is defined by a start point, a control point that implies the tangent at the start, a control point that implies the tangent at the end, and an end point, plus a characterizing matrix that we can multiply by that point vector to get on-curve coordinates.
- A Catmull-Rom curve is defined by a start point, a tangent that for that starting point, an end point, and a tangent for that end point, plus a characteristic matrix that we can multiple by the point vector to get on-curve coordinates.
Those are very similar, so let's see exactly how similar they are. We've already see the matrix form for Bézier curves, so how different is the matrix form for Catmull-Rom curves?:

That's pretty dang similar. So the question is: how can we convert that expression with Catmull-Rom matrix and vector into an expression of the Bézier matrix and vector? The short answer is of course "by using linear algebra", but the longer answer is the rest of this section, and involves some maths that you may not even care for: if you just want to know the (incredibly simple) conversions between the two curve forms, feel free to skip to the end of the following explanation, but if you want to how we can get one from the other... let's get mathing!
Deriving the conversion formulae
In order to convert between Catmull-Rom curves and Bézier curves, we need to know two things. Firstly, how to express the Catmull-Rom curve using a "set of four coordinates", rather than a mix of coordinates and tangents, and secondly, how to convert those Catmull-Rom coordinates to and from Bézier form.
We start with the first part, to figure out how we can go from Catmull-Rom V coordinates to Bézier P coordinates, by applying "some matrix T". We don't know what that T is yet, but we'll get to that:

So, this mapping says that in order to map a Catmull-Rom "point + tangent" vector to something based on an "all coordinates" vector, we need to determine the mapping matrix such that applying T yields P2 as start point, P3 as end point, and two tangents based on the lines between P1 and P3, and P2 nd P4, respectively.
Computing T is really more "arranging the numbers":

Thus:

However, we're not quite done, because Catmull-Rom curves have that "tension" parameter, written as τ (a lowercase"tau"), which is a scaling factor for the tangent vectors: the bigger the tension, the smaller the tangents, and the smaller the tension, the bigger the tangents. As such, the tension factor goes in the denominator for the tangents, and before we continue, let's add that tension factor into both our coordinate vector representation, and mapping matrix T:

With the mapping matrix properly done, let's rewrite the "point + tangent" Catmull-Rom matrix form to a matrix form in terms of four coordinates, and see what we end up with:

Replace point/tangent vector with the expression for all-coordinates:

and merge the matrices:

This looks a lot like the Bézier matrix form, which as we saw in the chapter on Bézier curves, should look like this:

So, if we want to express a Catmull-Rom curve using a Bézier curve, we'll need to turn this Catmull-Rom bit:

Into something that looks like this:

And the way we do that is with a fairly straight forward bit of matrix rewriting. We start with the equality we need to ensure:

Then we remove the coordinate vector from both sides without affecting the equality:

Then we can "get rid of" the Bézier matrix on the right by left-multiply both with the inverse of the Bézier matrix:

A matrix times its inverse is the matrix equivalent of 1, and because "something times 1" is the same as "something", so we can just outright remove any matrix/inverse pair:

And now we're basically done. We just multiply those two matrices and we know what V is:

We now have the final piece of our function puzzle. Let's run through each step.
- Start with the Catmull-Rom function:
- rewrite to pure coordinate form:

- rewrite for "normal" coordinate vector:

- merge the inner matrices:

- rewrite for Bézier matrix form:

- and transform the coordinates so we have a "pure" Bézier expression:

And we're done: we finally know how to convert these two curves!
If we have a Catmull-Rom curve defined by four coordinates P1 through P4, then we can draw that curve using a Bézier curve that has the vector:

Similarly, if we have a Bézier curve defined by four coordinates P1 through P4, we can draw that using a standard tension Catmull-Rom curve with the following coordinate values:

Or, if your API allows you to specify Catmull-Rom curves using plain coordinates:

Creating a Catmull-Rom curve from three points
Much shorter than the previous section: we saw that Catmull-Rom curves need at least 4 points to draw anything sensible, so how do we create a Catmull-Rom curve from three points?
Short and sweet: we don't.
We run through the maths that lets us create a cubic Bézier curve, and then convert its coordinates to Catmull-Rom form using the conversion formulae we saw above.
Forming poly-Bézier curves
Much like lines can be chained together to form polygons, Bézier curves can be chained together to form poly-Béziers, and the only trick required is to make sure that:
- the end point of each section is the starting point of the following section, and
- the derivatives across that dual point line up.
Unless you want sharp corners, of course. Then you don't even need 2.
We'll cover three forms of poly-Bézier curves in this section. First, we'll look at the kind that just follows point 1. where the end point of a segment is the same point as the start point of the next segment. This leads to poly-Béziers that are pretty hard to work with, but they're the easiest to implement:
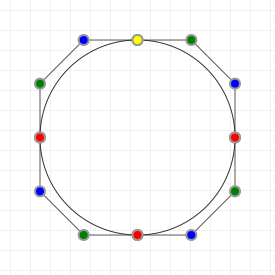
Dragging the control points around only affects the curve segments that the control point belongs to, and moving an on-curve point leaves the control points where they are, which is not the most useful for practical modelling purposes. So, let's add in the logic we need to make things a little better. We'll start by linking up control points by ensuring that the "incoming" derivative at an on-curve point is the same as it's "outgoing" derivative:

We can effect this quite easily, because we know that the vector from a curve's last control point to its last on-curve point is equal to the derivative vector. If we want to ensure that the first control point of the next curve matches that, all we have to do is mirror that last control point through the last on-curve point. And mirroring any point A through any point B is really simple:

So let's implement that and see what it gets us. The following two graphics show a quadratic and a cubic poly-Bézier curve again, but this time moving the control points around moves others, too. However, you might see something unexpected going on for quadratic curves...
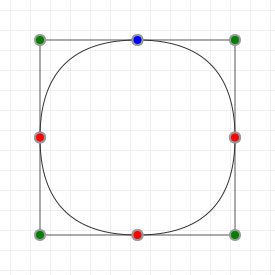
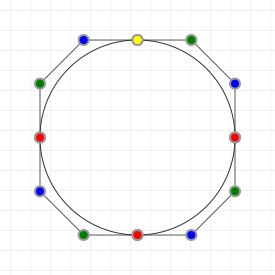
As you can see, quadratic curves are particularly ill-suited for poly-Bézier curves, as all the control points are effectively linked. Move one of them, and you move all of them. Not only that, but if we move the on-curve points, it's possible to get a situation where a control point cannot satisfy the constraint that it's the reflection of its two neighbouring control points... This means that we cannot use quadratic poly-Béziers for anything other than really, really simple shapes. And even then, they're probably the wrong choice. Cubic curves are pretty decent, but the fact that the derivatives are linked means we can't manipulate curves as well as we might if we relaxed the constraints a little.
So: let's relax the requirement a little.
We can change the constraint so that we still preserve the angle of the derivatives across sections (so transitions from one section to the next will still look natural), but give up the requirement that they should also have the same vector length. Doing so will give us a much more useful kind of poly-Bézier curve:
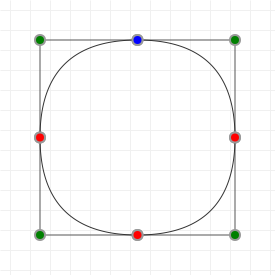
Cubic curves are now better behaved when it comes to dragging control points around, but the quadratic poly-Bézier still has the problem that moving one control points will move the control points and may ending up defining "the next" control point in a way that doesn't work. Quadratic curves really aren't very useful to work with...
Finally, we also want to make sure that moving the on-curve coordinates preserves the relative positions of the associated control points. With that, we get to the kind of curve control that you might be familiar with from applications like Photoshop, Inkscape, Blender, etc.
Again, we see that cubic curves are now rather nice to work with, but quadratic curves have a new, very serious problem: we can move an on-curve point in such a way that we can't compute what needs to "happen next". Move the top point down, below the left and right points, for instance. There is no way to preserve correct control points without a kink at the bottom point. Quadratic curves: just not that good...
A final improvement is to offer fine-level control over which points behave which, so that you can have "kinks" or individually controlled segments when you need them, with nicely well-behaved curves for the rest of the path. Implementing that, is left as an exercise for the reader.
Curve offsetting
Perhaps you're like me, and you've been writing various small programs that use Bézier curves in some way or another, and at some point you make the step to implementing path extrusion. But you don't want to do it pixel based; you want to stay in the vector world. You find that extruding lines is relatively easy, and tracing outlines is coming along nicely (although junction caps and fillets are a bit of a hassle), and then you decide to do things properly and add Bézier curves to the mix. Now you have a problem.
Unlike lines, you can't simply extrude a Bézier curve by taking a copy and moving it around, because of the curvatures; rather than a uniform thickness, you get an extrusion that looks too thin in places, if you're lucky, but more likely will self-intersect. The trick, then, is to scale the curve, rather than simply copying it. But how do you scale a Bézier curve?
Bottom line: you can't. So you cheat. We're not going to do true curve scaling, or rather curve offsetting, because that's impossible. Instead we're going to try to generate 'looks good enough' offset curves.
"What do you mean, you can't? Prove it."
First off, when I say "you can't," what I really mean is "you can't offset a Bézier curve with another Bézier curve", not even by using a really high order curve. You can find the function that describes the offset curve, but it won't be a polynomial, and as such it cannot be represented as a Bézier curve, which has to be a polynomial. Let's look at why this is:
From a mathematical point of view, an offset curve O(t) is a curve such that, given our original curve B(t),
any point on O(t) is a fixed distance d away from coordinate B(t). So let's math that:

However, we're working in 2D, and d is a single value, so we want to turn it into a vector. If we want a point distance
d "away" from the curve B(t) then what we really mean is that we want a point at d times the
"normal vector" from point B(t), where the "normal" is a vector that runs perpendicular ("at a right angle") to the tangent
at B(t). Easy enough:

Now this still isn't very useful unless we know what the formula for N(t) is, so let's find out. N(t) runs
perpendicular to the original curve tangent, and we know that the tangent is simply B'(t), so we could just rotate that 90
degrees and be done with it. However, we need to ensure that N(t) has the same magnitude for every t, or the
offset curve won't be at a uniform distance, thus not being an offset curve at all. The easiest way to guarantee this is to make sure
N(t) always has length 1, which we can achieve by dividing B'(t) by its magnitude:

The magnitude of B'(t), usually denoted with double vertical bars, is given by the following formula:

And that's where things go wrong: that square root is screwing everything up, because it turns our nice polynomials into things that are no longer polynomials.
There is a small class of polynomials where the square root is also a polynomial, but they're utterly useless to us: any polynomial with unweighted binomial coefficients has a square root that is also a polynomial. Now, you might think that Bézier curves are just fine because they do, but they don't; remember that only the base function has binomial coefficients. That's before we factor in our coordinates, which turn it into a non-binomial polygon. The only way to make sure the functions stay binomial is to make all our coordinates have the same value. And that's not a curve, that's a point. We can already create offset curves for points, we call them circles, and they have much simpler functions than Bézier curves.
So, since the tangent length isn't a polynomial, the normalised tangent won't be a polynomial either, which means
N(t) won't be a polynomial, which means that d times N(t) won't be a polynomial, which means
that, ultimately, O(t) won't be a polynomial, which means that even if we can determine the function for
O(t) just fine (and that's far from trivial!), it simply cannot be represented as a Bézier curve.
And that's one reason why Bézier curves are tricky: there are actually a lot of curves that cannot be represented as a Bézier curve at all. They can't even model their own offset curves. They're weird that way. So how do all those other programs do it? Well, much like we're about to do, they cheat. We're going to approximate an offset curve in a way that will look relatively close to what the real offset curve would look like, if we could compute it.
So, you cannot offset a Bézier curve perfectly with another Bézier curve, no matter how high-order you make that other Bézier curve.
However, we can chop up a curve into "safe" sub-curves (where "safe" means that all the control points are always on a single side of the
baseline, and the midpoint of the curve at t=0.5 is roughly in the center of the polygon defined by the curve coordinates)
and then point-scale each sub-curve with respect to its scaling origin (which is the intersection of the point normals at the start and
end points).
A good way to do this reduction is to first find the curve's extreme points, as explained in the earlier section on curve extremities, and
use these as initial splitting points. After this initial split, we can check each individual segment to see if it's "safe enough" based
on where the center of the curve is. If the on-curve point for t=0.5 is too far off from the center, we simply split the
segment down the middle. Generally this is more than enough to end up with safe segments.
The following graphics show off curve offsetting, and you can use the slider to control the distance at which the curve gets offset. The curve first gets reduced to safe segments, each of which is then offset at the desired distance. Especially for simple curves, particularly easily set up for quadratic curves, no reduction is necessary, but the more twisty the curve gets, the more the curve needs to be reduced in order to get segments that can safely be scaled.
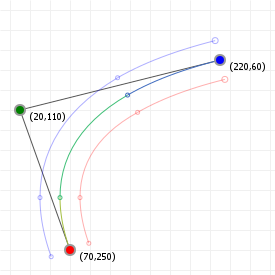
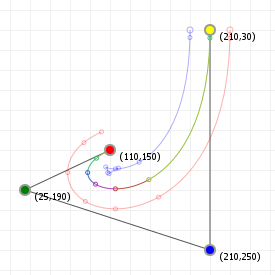
You may notice that this may still lead to small 'jumps' in the sub-curves when moving the curve around. This is caused by the fact that we're still performing a naive form of offsetting, moving the control points the same distance as the start and end points. If the curve is large enough, this may still lead to incorrect offsets.
Graduated curve offsetting
What if we want to do graduated offsetting, starting at some distance s but ending at some other distance e?
Well, if we can compute the length of a curve (which we can if we use the Legendre-Gauss quadrature approach) then we can also determine
how far "along the line" any point on the curve is. With that knowledge, we can offset a curve so that its offset curve is not uniformly
wide, but graduated between with two different offset widths at the start and end.
Like normal offsetting we cut up our curve in sub-curves, and then check at which distance along the original curve each sub-curve starts
and ends, as well as to which point on the curve each of the control points map. This gives us the distance-along-the-curve for each
interesting point in the sub-curve. If we call the total length of all sub-curves seen prior to seeing "the current" sub-curve
S (and if the current sub-curve is the first one, S is zero), and we call the full length of our original curve
L, then we get the following graduation values:
- start: map
Sfrom interval (0,L) to interval(s,e) - c1:
map(<strong>S+d1</strong>, 0,L, s,e), d1 = distance along curve to projection of c1 - c2:
map(<strong>S+d2</strong>, 0,L, s,e), d2 = distance along curve to projection of c2 - ...
- end:
map(<strong>S+length(subcurve)</strong>, 0,L, s,e)
At each of the relevant points (start, end, and the projections of the control points onto the curve) we know the curve's normal, so offsetting is simply a matter of taking our original point, and moving it along the normal vector by the offset distance for each point. Doing so will give us the following result (these have with a starting width of 0, and an end width of 40 pixels, but can be controlled with your up and down arrow keys):
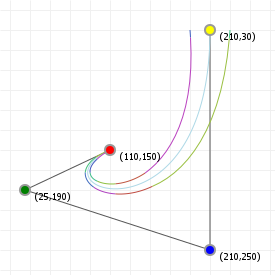
Circles and quadratic Bézier curves
Circles and Bézier curves are very different beasts, and circles are infinitely easier to work with than Bézier curves. Their formula is much simpler, and they can be drawn more efficiently. But, sometimes you don't have the luxury of using circles, or ellipses, or arcs. Sometimes, all you have are Bézier curves. For instance, if you're doing font design, fonts have no concept of geometric shapes, they only know straight lines, and Bézier curves. OpenType fonts with TrueType outlines only know quadratic Bézier curves, and OpenType fonts with Type 2 outlines only know cubic Bézier curves. So how do you draw a circle, or an ellipse, or an arc?
You approximate.
We already know that Bézier curves cannot model all curves that we can think of, and this includes perfect circles, as well as ellipses, and their arc counterparts. However, we can certainly approximate them to a degree that is visually acceptable. Quadratic and cubic curves offer us different curvature control, so in order to approximate a circle we will first need to figure out what the error is if we try to approximate arcs of increasing degree with quadratic and cubic curves, and where the coordinates even lie.
Since arcs are mid-point-symmetrical, we need the control points to set up a symmetrical curve. For quadratic curves this means that the control point will be somewhere on a line that intersects the baseline at a right angle. And we don't get any choice on where that will be, since the derivatives at the start and end point have to line up, so our control point will lie at the intersection of the tangents at the start and end point.
First, let's try to fit the quadratic curve onto a circular arc. In the following sketch you can move the mouse around over a unit circle, to see how well, or poorly, a quadratic curve can approximate the arc from (1,0) to where your mouse cursor is:
As you can see, things go horribly wrong quite quickly; even trying to approximate a quarter circle using a quadratic curve is a bad idea. An eighth of a turns might look okay, but how okay is okay? Let's apply some maths and find out. What we're interested in is how far off our on-curve coordinates are with respect to a circular arc, given a specific start and end angle. We'll be looking at how much space there is between the circular arc, and the quadratic curve's midpoint.
We start out with our start and end point, and for convenience we will place them on a unit circle (a circle around 0,0 with radius 1), at some angle φ:

What we want to find is the intersection of the tangents, so we want a point C such that:

i.e. we want a point that lies on the vertical line through S (at some distance a from S) and also lies on the tangent line through E (at some distance b from E). Solving this gives us:

First we solve for b:

which yields:

which we can then substitute in the expression for a:

A quick check shows that plugging these values for a and b into the expressions for Cx and Cy give the same x/y coordinates for both "a away from A" and "b away from B", so let's continue: now that we know the coordinate values for C, we know where our on-curve point T for t=0.5 (or angle φ/2) is, because we can just evaluate the Bézier polynomial, and we know where the circle arc's actual point P is for angle φ/2:

We compute T, observing that if t=0.5, the polynomial values (1-t)², 2(1-t)t, and t² are 0.25, 0.5, and 0.25 respectively:

Which, worked out for the x and y components, gives:

And the distance between these two is the standard Euclidean distance:

So, what does this distance function look like when we plot it for a number of ranges for the angle φ, such as a half circle, quarter circle and eighth circle?
 plotted for 0 ≤ φ ≤ π:
plotted for 0 ≤ φ ≤ π:
|
 plotted for 0 ≤ φ ≤ ½π:
plotted for 0 ≤ φ ≤ ½π:
|
 plotted for 0 ≤ φ ≤ ¼π:
plotted for 0 ≤ φ ≤ ¼π:
|
We now see why the eighth circle arc looks decent, but the quarter circle arc doesn't: an error of roughly 0.06 at t=0.5 means we're 6% off the mark... we will already be off by one pixel on a circle with pixel radius 17. Any decent sized quarter circle arc, say with radius 100px, will be way off if approximated by a quadratic curve! For the eighth circle arc, however, the error is only roughly 0.003, or 0.3%, which explains why it looks so close to the actual eighth circle arc. In fact, if we want a truly tiny error, like 0.001, we'll have to contend with an angle of (rounded) 0.593667, which equates to roughly 34 degrees. We'd need 11 quadratic curves to form a full circle with that precision! (technically, 10 and ten seventeenth, but we can't do partial curves, so we have to round up). That's a whole lot of curves just to get a shape that can be drawn using a simple function!
In fact, let's flip the function around, so that if we plug in the precision error, labelled ε, we get back the maximum angle for that precision:

And frankly, things are starting to look a bit ridiculous at this point, we're doing way more maths than we've ever done, but thankfully this is as far as we need the maths to take us: If we plug in the precisions 0.1, 0.01, 0.001 and 0.0001 we get the radians values 1.748, 1.038, 0.594 and 0.3356; in degrees, that means we can cover roughly 100 degrees (requiring four curves), 59.5 degrees (requiring six curves), 34 degrees (requiring 11 curves), and 19.2 degrees (requiring a whopping nineteen curves).
The bottom line? Quadratic curves are kind of lousy if you want circular (or elliptical, which are circles that have been squashed in one dimension) curves. We can do better, even if it's just by raising the order of our curve once. So let's try the same thing for cubic curves.
Circular arcs and cubic Béziers
Let's look at approximating circles and circular arcs using cubic Béziers. How much better is that?
At cursory glance, a fair bit better, but let's find out how much better by looking at how to construct the Bézier curve.
The start and end points are trivial, but the mid point requires a bit of work, but it's mostly basic trigonometry once we know the angle θ for our circular arc: if we scale our circular arc to a unit circle, we can always start our arc, with radius 1, at (1,0) and then given our arc angle θ, we also know that the circular arc has length θ (because unit circles are nice that way). We also know our end point, because that's just (cos(θ), sin(θ)), and so the challenge is to figure out what control points we need in order for the curve at t=0.5 to exactly touch the circular arc at the angle θ/2:
So let's again formally describe this:

Only P3 isn't quite straight-forward here, and its description is based on the fact that the triangle (origin, P4, P3) is a right angled triangle, with the distance between the origin and P4 being 1 (because we're working with a unit circle), and the distance between P4 and P3 being k, so that we can represent P3 as "The point P4 plus the vector from the origin to P4 but then rotated a quarter circle, counter-clockwise, and scaled by k".
With that, we can determine the y-coordinates for A, B, e1, and e2, after which we have all the information we need to determine what the value of k is. We can find these values by using (no surprise here) linear interpolation between known points, as A is midway between P2 and P3, e1 is between A and "midway between P1 and P2" (which is "half height" P2), and so forth:

Which now gives us two identities for B, because in addition to determining B through linear interpolation, we also know that B's y coordinate is just sin(θ/2): we started this exercise by saying we were going to approximate the circular arc using a Bézier curve that had its midpoint, which is point B, touching the unit circle at the arc's half-angle, by definition making B the point at (cos(θ/2), sin(θ/2)).
This means we can equate the two identities we now have for By and solve for k.
Deriving k
Solving for k is fairly straight forward, but it's a fair few steps, and if you just the immediate result: using a tool like Wolfram Alpha is definitely the way to go. That said, let's get going:

And finally, we can take further advantage of several trigonometric identities to drastically simplify our formula for k:

And we're done.
So, the distance of our control points to the start/end points can be expressed as a number that we get from an almost trivial expression involving the circular arc's angle:

Which means that for any circular arc with angle θ and radius r, our Bézier approximation based on three points of incidence is:

Which also gives us the commonly found value of 0.55228 for quarter circles, based on them having an angle of half π:

And thus giving us the following Bézier coordinates for a quarter circle of radius r:

So, how accurate is this?
Unlike for the quadratic curve, we can't use t=0.5 as our reference point because by its very nature it's one of the three points that are actually guaranteed to be on the circular arc itself. Instead, we need a different t value that will give us the maximum deflection - there are two possible choices (as our curve is still strictly "overshoots" the circular arc, and it's symmetrical) but rather than trying to use calculus to find the perfect t value—which we could! the maths is perfectly reasonable as long as we get to use computers—we can also just perform a binary search for the biggest deflection and not bother with all this maths stuff.
So let's do that instead: we can run a maximum deflection check that just runs through t from 0 to 1 at some coarse interval, finds a t value that has "the highest deflection of the bunch", then reruns the same check with a much smaller interval around that t value, repeating as many times as necessary to get us an arbitrarily precise value of t:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 |
Plus, how often do you get to write a function with that name?
Using this code, we find that our t values are approximately 0.211325 and 0.788675, so let's pick the lower of the two and see what the maximum deflection is across our domain of angles, with the original quadratic error show in green (rocketing off to infinity first, and then coming back down as we approach 2π)
|
|
|
| error plotted for 0 ≤ φ ≤ 2π | error plotted for 0 ≤ φ ≤ π | error plotted for 0 ≤ φ ≤ ½π |
That last image is probably not quite clear enough: the cubic approximation of a quarter circle is so incredibly much better that we can't even really see it at the same scale of our quadratic curve. Let's scale the y-axis a little, and try that again:
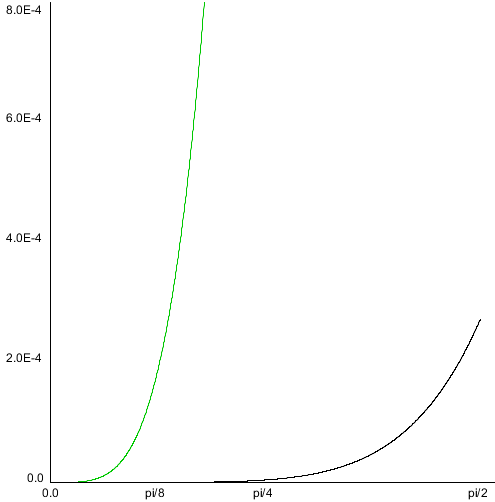
Yeah... the error of a cubic approximation for a quarter circle turns out to be two orders of magnitude better. At approximately 0.00027 (or: just shy of being 2.7 pixels off for a circle with a radius of 10,000 pixels) the increase in precision over quadratic curves is quite spectacular - certainly good enough that no one in their right mind should ever use quadratic curves.
So that's it, kappa is 4/3 · tan(θ/4) , we're done! ...or are we?
Can we do better?
Technically: yes, we can. But I'm going to prefix this section with "we can, and we should investigate that possibility, but let me warn you up front that the result is only better if we're going to hard-code the values". We're about to get into the weeds and the standard three-points-of-incidence value is so good already that for most applications, trying to do better won't make any sense at all.
So with that said: what we calculated above is an upper bound for a best fit Bézier curve for a circular arc: anywhere we don't touch the circular arc in our approximation, we've "overshot" the arc. What if we dropped our value for k just a little, so that the curve starts out as an over-estimation, but then crosses the circular arc, yielding an region of underestimation, and then crosses the circular arc again, with another region of overestimation. This might give us a lower overall error, so let's see what we can do.
First, let's express the total error (given circular arc angle θ, and some k) using standard calculus notation:

This says that the error function for a given angle and value of k is equal to the "infinite" sum of differences between our curve and the circular arc, as we run t from 0 to 1, using an infinitely small step size. between subsequent t values.
Now, since we want to find the minimal error, that means we want to know where along this function things go from "error is getting progressively less" to "error is increasing again", which means we want to know where its derivative is zero, which as mathematical expression looks like:

And here we have the most direct application of the Fundamental Theorem of Calculus: the derivative and integral are each other's inverse operations, so they cancel out, leaving us with our original function:

And now we just solve for that... oh wait. We've seen this before. In order to solve this, we'd end up needing to solve this:

And both of those terms on the left of the equal sign are 6th degree polynomials, which means—as we've covered in the section on arc lengths—there is no symbolic solution for this equasion. Instead, we'll have to use a numerical approach to find the solutions here, so... to the computer!
Iterating on a solution
By which I really mean "to the binary search algorithm", because we're dealing with a reasonably well behaved function: depending on the value for k , we're either going to end up with a Bézier curve that's on average "not at distance r from the arc's center", "exactly distance r from the arc's center", or "more than distance r from the arc's center", so we can just binary search our way to the most accurate value for c that gets us that middle case.
First our setup, where we determine our upper and lower bounds, before entering our binary search:
| 1 | |
| 2 | |
| 3 | |
| 4 |
And then the binary search algorithm, which can be found in pretty much any CS textbook, as well as more online articles, tutorials, and blog posts than you can ever read in a life time:
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 | |
| 14 | |
| 15 | |
| 16 | |
| 17 | |
| 18 | |
| 19 |
Using the following radialError function, which samples the curve's approximation of the circular arc over several points
(although the first and last point will never contribute anything, so we skip them):
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 |
In this, getOnCurvePoint is just the standard Bézier evaluation function, yielding a point. Treating that point as a
vector, we can get its length to the origin using a magnitude call.
Examining the result
Running the above code we can get a list of k values associated with a list of angles θ from 0 to π, and we can use that to, for each angle, plot what the difference between the circular arc and the Bézier approximation looks like:
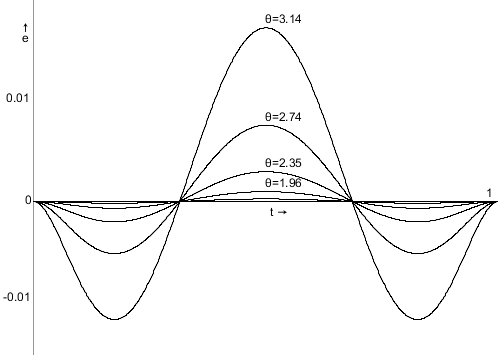
Here we see the difference between an arc and its Bézier approximation plotted as we run t from 0 to 1. Just by looking at the plot we can tell that there is maximum deflection at t = 0.5, so let's plot the maximum deflection "function", for angles from 0 to θ:
In fact, let's plot the maximum deflections for both approaches as a functions over θ:
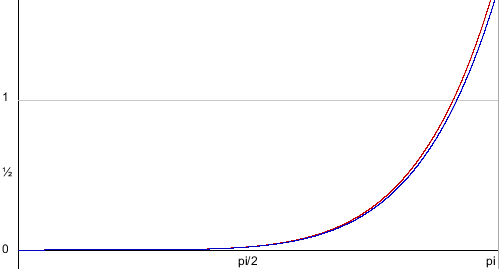
|
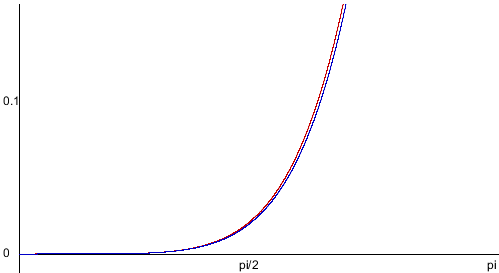
|
|
| max deflection using unit scale | max deflection at 10x scale | max deflection at 100x scale |
That doesn't actually appear to be all that much better, so let's look at some numbers, to see what the improvement actually is:
| angle | "improved" deflection | "upper bound" deflection | difference |
|---|---|---|---|
| 1/8 π | 6.202833502388927E-8 | 6.657161222278773E-8 | 4.5432771988984655E-9 |
| 1/4 π | 3.978021202111215E-6 | 4.246252911066506E-6 | 2.68231708955291E-7 |
| 3/8 π | 4.547652269037972E-5 | 4.8397483513262785E-5 | 2.9209608228830675E-6 |
| 1/2 π | 2.569196199214696E-4 | 2.7251652752280364E-4 | 1.559690760133403E-5 |
| 5/8 π | 9.877526288810667E-4 | 0.0010444175859711802 | 5.666495709011343E-5 |
| 3/4 π | 0.00298164978679627 | 0.0031455628414580605 | 1.6391305466179062E-4 |
| 7/8 π | 0.0076323182807019885 | 0.008047777909948373 | 4.1545962924638413E-4 |
| π | 0.017362185964043708 | 0.018349016519545902 | 9.86830555502194E-4 |
As we can see, the increase in precision is not particularly big: for a quarter circle (π/2) the traditional k will be off by 2.75 pixels on a circle with radius 10,000 pixels, whereas this "better" fit will be off by 2.56 pixels. And while that's certainly an almost 10% improvement, it's also nowhere near enough of an improvement to make a discernible difference.
At this point it should be clear that while, yes, there are improvement to be had, they're essentially insignificant while also being much more computationally expensive.
TL;DR: just tell me which value I should be using
It depends on what we need to do. If we just want the best value for quarter circles, and we're going to hard code the value for
k, then there is no reason to hard-code the constant k=4/3*tan(pi/8) when you can just as easily hard-code the
constant as k=0.551784777779014 instead.
If you need "the" value for quarter circles, use 0.551785 instead of 0.55228
However, for dynamic arc approximation, in code that tries to fit circular paths using Bézier paths instead, it should be fairly obvious that the simple function involving a tangent computation, two divisions, and one multiplication, is vastly more performant than running all the code we ended writing just to get a 25% lower error value, and most certainly worth preferring over getting the "more accurate" value.
If you need to fit Béziers to circular arcs on the fly, use 4/3 * tan(θ/4)
However, always remember that if you're writing for humans, you can typically use the best of both worlds: as the user interacts with their curves, you should draw their curves instead of drawing approximations of them. If they need to draw circles or circular arcs, draw those, and only approximate them with a Bézier curve when the data needs to be exported to a format that doesn't support those. Ideally with a preview mechanism that highlights where the errors will be, and how large they will be.
If you're writing code for graphics design by humans, use circular arcs for circular arcs
And that's it. We have pretty well exhausted this subject. There are different metrics we could use to find "different best k values", like trying to match arc length (e.g. when we're optimizing for material cost), or minimizing the area between the circular arc and the Bézier curve (e.g. when we're optimizing for inking), or minimizing the rate of change of the Bézier's curvature (e.g. when we're optimizing for curve traversal) and they all yield values that are so similar that it's almost certainly not worth it. (For instance, for quarter circle approximations those values are 0.551777, 0.5533344, and 0.552184 respectively. Much like the 0.551785 we get from minimizing the maximum deflection, none of these values are significantly better enough to prefer them over the upper bound value).
Approximating Bézier curves with circular arcs
Let's look at doing the exact opposite of the previous section: rather than approximating circular arc using Bézier curves, let's approximate Bézier curves using circular arcs.
We already saw in the section on circle approximation that this will never yield a perfect equivalent, but sometimes you need circular arcs, such as when you're working with fabrication machinery, or simple vector languages that understand lines and circles, but not much else.
The approach is fairly simple: pick a starting point on the curve, and pick two points that are further along the curve. Determine the circle that goes through those three points, and see if it fits the part of the curve we're trying to approximate. Decent fit? Try spacing the points further apart. Bad fit? Try spacing the points closer together. Keep doing this until you've found the "good approximation/bad approximation" boundary, record the "good" arc, and then move the starting point up to overlap the end point we previously found. Rinse and repeat until we've covered the entire curve.
We already saw how to fit a circle through three points in the section on creating a curve from three points, and finding the arc through those points is straight-forward: pick one of the three points as start point, pick another as an end point, and the arc has to necessarily go from the start point, to the end point, over the remaining point.
So, how can we convert a Bézier curve into a (sequence of) circular arc(s)?
- Start at
t=0 - Pick two points further down the curve at some value
m = t + nande = t + 2n - Find the arc that these points define
-
Determine how close the found arc is to the curve:
- Pick two additional points
e1 = t + n/2ande2 = t + n + n/2. -
These points, if the arc is a good approximation of the curve interval chosen, should lie
onthe circle, so their distance to the center of the circle should be the same as the distance from any of the three other points to the center. -
For point points, determine the (absolute) error between the radius of the circle, and the
actualdistance from the center of the circle to the point on the curve. - If this error is too high, we consider the arc bad, and try a smaller interval.
- Pick two additional points
The result of this is shown in the next graphic: we start at a guaranteed failure: s=0, e=1. That's the entire curve. The midpoint is
simply at t=0.5, and then we start performing a
binary search.
- We start with
low=0,mid=0.5andhigh=1 -
That'll fail, so we retry with the interval halved:
{0, 0.25, 0.5}- If that arc's good, we move back up by half distance:
{0, 0.375, 0.75}. - However, if the arc was still bad, we move down by half the distance:
{0, 0.125, 0.25}.
- If that arc's good, we move back up by half distance:
- We keep doing this over and over until we have two arcs, in sequence, of which the first arc is good, and the second arc is bad. When we find that pair, we've found the boundary between a good approximation and a bad approximation, and we pick the good arc.
The following graphic shows the result of this approach, with a default error threshold of 0.5, meaning that if an arc is off by a combined half pixel over both verification points, then we treat the arc as bad. This is an extremely simple error policy, but already works really well. Note that the graphic is still interactive, and you can use your up and down arrow keys keys to increase or decrease the error threshold, to see what the effect of a smaller or larger error threshold is.
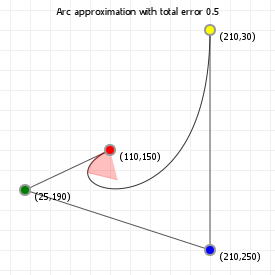
With that in place, all that's left now is to "restart" the procedure by treating the found arc's end point as the new to-be-determined arc's starting point, and using points further down the curve. We keep trying this until the found end point is for t=1, at which point we are done. Again, the following graphic allows for up and down arrow key input to increase or decrease the error threshold, so you can see how picking a different threshold changes the number of arcs that are necessary to reasonably approximate a curve:
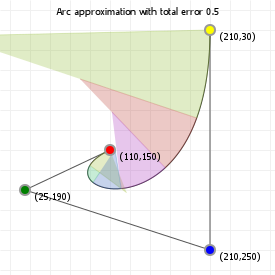
So... what is this good for? Obviously, if you're working with technologies that can't do curves, but can do lines and circles, then the answer is pretty straightforward, but what else? There are some reasons why you might need this technique: using circular arcs means you can determine whether a coordinate lies "on" your curve really easily (simply compute the distance to each circular arc center, and if any of those are close to the arc radii, at an angle between the arc start and end, bingo, this point can be treated as lying "on the curve"). Another benefit is that this approximation is "linear": you can almost trivially travel along the arcs at fixed speed. You can also trivially compute the arc length of the approximated curve (it's a bit like curve flattening). The only thing to bear in mind is that this is a lossy equivalence: things that you compute based on the approximation are guaranteed "off" by some small value, and depending on how much precision you need, arc approximation is either going to be super useful, or completely useless. It's up to you to decide which, based on your application!
B-Splines
No discussion on Bézier curves is complete without also giving mention of that other beast in the curve design space: B-Splines. Easily confused to mean Bézier splines, that's not actually what they are; they are "basis function" splines, which makes a lot of difference, and we'll be looking at those differences in this section. We're not going to dive as deep into B-Splines as we have for Bézier curves (that would be an entire primer on its own) but we'll be looking at how B-Splines work, what kind of maths is involved in computing them, and how to draw them based on a number of parameters that you can pick for individual B-Splines.
First off: B-Splines are piecewise, polynomial interpolation curves, where the "single curve" is built by performing polynomial interpolation over a set of points, using a sliding window of a fixed number of points. For instance, a "cubic" B-Spline defined by twelve points will have its curve built by evaluating the polynomial interpolation of four points, and the curve can be treated as a lot of different sections, each controlled by four points at a time, such that the full curve consists of smoothly connected sections defined by points {1,2,3,4}, {2,3,4,5}, ..., {8,9,10,11}, and finally {9,10,11,12}, for eight sections.
What do they look like? They look like this! Tap on the graphic to add more points, and move points around to see how they map to the spline curve drawn.
The important part to notice here is that we are not doing the same thing with B-Splines that we do for poly-Béziers or Catmull-Rom curves: both of the latter simply define new sections as literally "new sections based on new points", so a 12 point cubic poly-Bézier curve is actually impossible, because we start with a four point curve, and then add three more points for each section that follows, so we can only have 4, 7, 10, 13, 16, etc. point Poly-Béziers. Similarly, while Catmull-Rom curves can grow by adding single points, this addition of a single point introduces three implicit Bézier points. Cubic B-Splines, on the other hand, are smooth interpolations of each possible curve involving four consecutive points, such that at any point along the curve except for our start and end points, our on-curve coordinate is defined by four control points.
Consider the difference to be this:
- for Bézier curves, the curve is defined as an interpolation of points, but:
- for B-Splines, the curve is defined as an interpolation of curves.
In fact, let's look at that again, but this time with the base curves shown, too. Each consecutive four points define one curve:
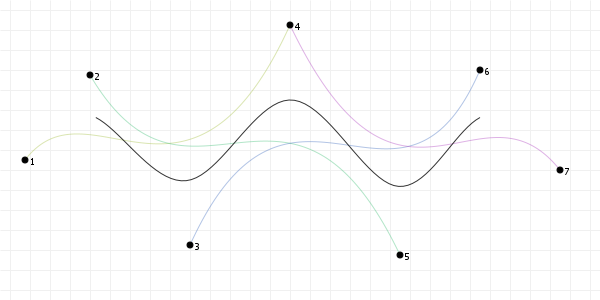
In order to make this interpolation of curves work, the maths is necessarily more complex than the maths for Bézier curves, so let's have a look at how things work.
How to compute a B-Spline curve: some maths
Given a B-Spline of degree d and thus order k=d+1 (so a quadratic B-Spline is degree 2 and order 3, a cubic
B-Spline is degree 3 and order 4, etc) and n control points P0 through Pn-1, we can compute a point on the curve for some value t in the interval [0,1] (where 0 is the start of the curve, and 1 the
end, just like for Bézier curves), by evaluating the following function:

Which, honestly, doesn't tell us all that much. All we can see is that a point on a B-Spline curve is defined as "a mix of all the control
points, weighted somehow", where the weighting is achieved through the N(...) function, subscripted with an obvious parameter
i, which comes from our summation, and some magical parameter k. So we need to know two things: 1. what does
N(t) do, and 2. what is that k? Let's cover both, in reverse order.
The parameter k represents the "knot interval" over which a section of curve is defined. As we learned earlier, a B-Spline
curve is itself an interpolation of curves, and we can treat each transition where a control point starts or stops influencing the total
curvature as a "knot on the curve". Doing so for a degree d B-Spline with n control point gives us
d + n + 1 knots, defining d + n intervals along the curve, and it is these intervals that the above
k subscript to the N() function applies to.
Then the N() function itself. What does it look like?

So this is where we see the interpolation: N(t) for an (i,k) pair (that is, for a step in the above summation, on a specific
knot interval) is a mix between N(t) for (i,k-1) and N(t) for (i+1,k-1), so we see that this is a recursive
iteration where i goes up, and k goes down, so it seem reasonable to expect that this recursion has to stop at
some point; obviously, it does, and specifically it does so for the following i/k values:

And this function finally has a straight up evaluation: if a t value lies within a knot-specific interval once we reach a
k=1 value, it "counts", otherwise it doesn't. We did cheat a little, though, because for all these values we need to scale
our t value first, so that it lies in the interval bounded by knots[d] and knots[n], which are the
start point and end point where curvature is controlled by exactly order control points. For instance, for degree 3 (=order
4) and 7 control points, with knot vector [1,2,3,4,5,6,7,8,9,10,11], we map t from [the interval 0,1] to the interval [4,8],
and then use that value in the functions above, instead.
Can we simplify that?
We can, yes.
People far smarter than us have looked at this work, and two in particular —
Maurice Cox and
Carl de Boor — came to a mathematically pleasing solution: to compute a point
P(t), we can compute this point by evaluating d(t) on a curve section between knots i and i+1:

This is another recursive function, with k values decreasing from the curve order to 1, and the value α (alpha) defined by:

That looks complicated, but it's not. Computing alpha is just a fraction involving known, plain numbers. And, once we have our alpha
value, we also have (1-alpha) because it's a trivial subtraction. Computing the d() function is thus mostly a
matter of computing pretty simple arithmetical statements, with some caching of results so we can refer to them as we recurve. While the
recursion might see computationally expensive, the total algorithm is cheap, as each step only involves very simple maths.
Of course, the recursion does need a stop condition:

So, we actually see two stopping conditions: either i becomes 0, in which case d() is zero, or
k becomes zero, in which case we get the same "either 1 or 0" that we saw in the N() function above.
Thanks to Cox and de Boor, we can compute points on a B-Spline pretty easily using the same kind of linear interpolation we saw in de
Casteljau's algorithm. For instance, if we write out d() for i=3 and k=3, we get the following
recursion diagram:

That is, we compute d(3,3) as a mixture of d(2,3) and d(2,2), where those two are themselves a
mixture of d(1,3) and d(1,2), and d(1,2) and d(1,1), respectively, which are
themselves a mixture of etc. etc. We simply keep expanding our terms until we reach the stop conditions, and then sum everything back up.
It's really quite elegant.
One thing we need to keep in mind is that we're working with a spline that is constrained by its control points, so even though the
d(..., k) values are zero or one at the lowest level, they are really "zero or one, times their respective control point", so
in the next section you'll see the algorithm for running through the computation in a way that starts with a copy of the control point
vector and then works its way up to that single point, rather than first starting "on the left", working our way "to the right" and then
summing back up "to the left". We can just start on the right and work our way left immediately.
Running the computation
Unlike the de Casteljau algorithm, where the t value stays the same at every iteration, for B-Splines that is not the case,
and so we end having to (for each point we evaluate) run a fairly involving bit of recursive computation. The algorithm is discussed on
this Michigan Tech page, but an easier to read version
is implemented by b-spline.js, so we'll look at its code.
Given an input value t, we first map the input to a value from the domain [0,1] to the domain
[knots[degree], knots[knots.length - 1 - degree]. Then, we find the section number s that this mapped
t value lies on:
| 1 | |
| 2 | |
| 3 |
after running this code, s is the index for the section the point will lie on. We then run the algorithm mentioned on the MU
page (updated to use this description's variable names):
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 |
(A nice bit of behaviour in this code is that we work the interpolation "backwards", starting at i=s at each level of the
interpolation, and we stop when i = s - order + level, so we always end up with a value for i such that those
v[i-1] don't try to use an array index that doesn't exist)
Open vs. closed paths
Much like poly-Béziers, B-Splines can be either open, running from the first point to the last point, or closed, where the first and last
point are the same coordinate. However, because B-Splines are an interpolation of curves, not just points, we can't simply make the first
and last point the same, we need to link as many points as are necessary to form "a curve" that the spline performs interpolation with. As
such, for an order d B-Spline, we need to make the first and last d points the same. This is of course hardly
more work than before (simply append points.splice(0,d) to points) but it's important to remember that you need
more than just a single point.
Of course if we want to manipulate these kind of curves we need to make sure to mark them as "closed" so that we know the coordinate for
points[0] and points[n-k] etc. don't just happen to have the same x/y values, but really are the same
coordinate, so that manipulating one will equally manipulate the other, but programming generally makes this really easy by storing
references to points, rather than copies (or other linked values such as coordinate weights, discussed in the NURBS section) rather than
separate coordinate objects.
Manipulating the curve through the knot vector
The most important thing to understand when it comes to B-Splines is that they work because of the concept of a knot vector. As mentioned above, knots represent "where individual control points start/stop influencing the curve", but we never looked at the values that go in the knot vector. If you look back at the N() and a() functions, you see that interpolations are based on intervals in the knot vector, rather than the actual values in the knot vector, and we can exploit this to do some pretty interesting things with clever manipulation of the knot vector. Specifically there are four things we can do that are worth looking at:
- we can use a uniform knot vector, with equally spaced intervals,
- we can use a non-uniform knot vector, without enforcing equally spaced intervals,
- we can collapse sequential knots to the same value, locally lowering curve complexity using "null" intervals, and
- we can form a special case non-uniform vector, by combining (1) and (3) to for a vector with collapsed start and end knots, with a uniform vector in between.
Uniform B-Splines
The most straightforward type of B-Spline is the uniform spline. In a uniform spline, the knots are distributed uniformly over the entire curve interval. For instance, if we have a knot vector of length twelve, then a uniform knot vector would be [0,1,2,3,...,9,10,11]. Or [4,5,6,...,13,14,15], which defines the same intervals, or even [0,2,3,...,18,20,22], which also defines the same intervals, just scaled by a constant factor, which becomes normalised during interpolation and so does not contribute to the curvature.
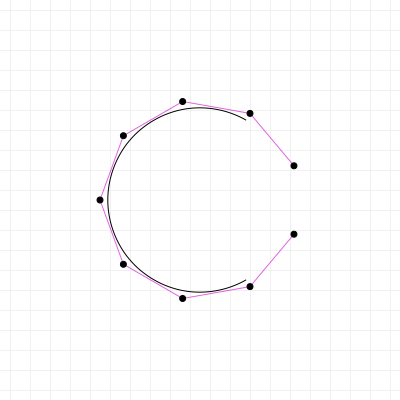
This is an important point: the intervals that the knot vector defines are relative intervals, so it doesn't matter if every interval is size 1, or size 100 - the relative differences between the intervals is what shapes any particular curve.
The problem with uniform knot vectors is that, as we need order control points before we have any curve with which we can
perform interpolation, the curve does not "start" at the first point, nor "ends" at the last point. Instead there are "gaps". We can get
rid of these, by being clever about how we apply the following uniformity-breaking approach instead...
Reducing local curve complexity by collapsing intervals
Collapsing knot intervals, by making two or more consecutive knots have the same value, allows us to reduce the curve complexity in the
sections that are affected by the knots involved. This can have drastic effects: for every interval collapse, the curve order goes down,
and curve continuity goes down, to the point where collapsing order knots creates a situation where all continuity is lost
and the curve "kinks".
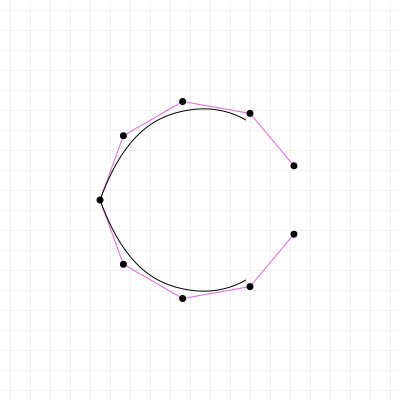
Open-Uniform B-Splines
By combining knot interval collapsing at the start and end of the curve, with uniform knots in between, we can overcome the problem of the curve not starting and ending where we'd kind of like it to:
For any curve of degree D with control points N, we can define a knot vector of length N+D+1 in
which the values 0 ... D+1 are the same, the values D+1 ... N+1 follow the "uniform" pattern, and the values
N+1 ... N+D+1 are the same again. For example, a cubic B-Spline with 7 control points can have a knot vector
[0,0,0,0,1,2,3,4,4,4,4], or it might have the "identical" knot vector [0,0,0,0,2,4,6,8,8,8,8], etc. Again, it is the relative differences
that determine the curve shape.
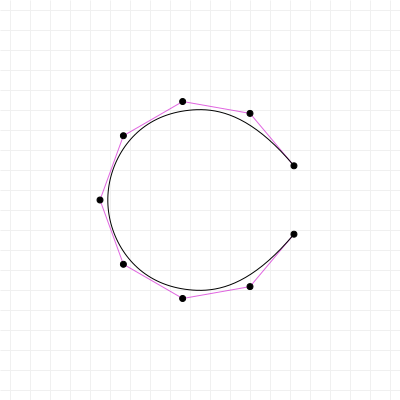
Non-uniform B-Splines
This is essentially the "free form" version of a B-Spline, and also the least interesting to look at, as without any specific reason to
pick specific knot intervals, there is nothing particularly interesting going on. There is one constraint to the knot vector, other than
that any value knots[k+1] should be greater than or equal to knots[k].
One last thing: Rational B-Splines
While it is true that this section on B-Splines is running quite long already, there is one more thing we need to talk about, and that's "Rational" splines, where the rationality applies to the "ratio", or relative weights, of the control points themselves. By introducing a ratio vector with weights to apply to each control point, we greatly increase our influence over the final curve shape: the more weight a control point carries, the closer to that point the spline curve will lie, a bit like turning up the gravity of a control point, just like for rational Bézier curves.
Of course this brings us to the final topic that any text on B-Splines must touch on before calling it a day: the NURBS, or Non-Uniform Rational B-Spline (NURBS is not a plural, the capital S actually just stands for "spline", but a lot of people mistakenly treat it as if it is, so now you know better). NURBS is an important type of curve in computer-facilitated design, used a lot in 3D modelling (typically as NURBS surfaces) as well as in arbitrary-precision 2D design due to the level of control a NURBS curve offers designers.
While a true non-uniform rational B-Spline would be hard to work with, when we talk about NURBS we typically mean the Open-Uniform Rational B-Spline, or OURBS, but that doesn't roll off the tongue nearly as nicely, and so remember that when people talk about NURBS, they typically mean open-uniform, which has the useful property of starting the curve at the first control point, and ending it at the last.
Extending our implementation to cover rational splines
The algorithm for working with Rational B-Splines is virtually identical to the regular algorithm, and the extension to work in the control point weights is fairly simple: we extend each control point from a point in its original number of dimensions (2D, 3D, etc.) to one dimension higher, scaling the original dimensions by the control point's weight, and then assigning that weight as its value for the extended dimension.
For example, a 2D point (x,y) with weight w becomes a 3D point (w * x, w * y, w).
We then run the same algorithm as before, which will automatically perform weight interpolation in addition to regular coordinate interpolation, because all we've done is pretended we have coordinates in a higher dimension. The algorithm doesn't really care about how many dimensions it needs to interpolate.
In order to recover our "real" curve point, we take the final result of the point generation algorithm, and "unweigh" it: we take the
final point's derived weight w' and divide all the regular coordinate dimensions by it, then throw away the weight
information.
Based on our previous example, we take the final 3D point (x', y', w'), which we then turn back into a 2D point by computing
(x'/w', y'/w'). And that's it, we're done!
First off, if you enjoyed this book, or you simply found it useful for something you were trying to get done, and you were wondering how to let me know you appreciated this book, you have two options: you can either head on over to the Patreon page for this book, or if you prefer to make a one-time donation, head on over to the buy Pomax a coffee page. This work has grown from a small primer to a 70-plus print-page-equivalent reader on the subject of Bézier curves over the years, and a lot of coffee went into the making of it. I don't regret a minute I spent on writing it, but I can always do with some more coffee to keep on writing.
With that said, on to the comments!